MySQL 是一个开源的关系型数据库管理系统(RDBMS),以其高性能、高可靠性和易用性而闻名,广泛应用于互联网、企业级系统、嵌入式设备等各类场景。以下从核心功能、核心特点、核心架构与算法三个维度,结合底层原理,对 MySQL 进行全面解析,呈现各模块之间的支撑关系。
一、核心功能与特性
MySQL 的核心功能围绕数据的存储、操作、安全、并发和高可用展开,覆盖从基础数据管理到企业级复杂场景的全需求,结合其核心特性,形成了灵活、高效、可靠的数据库解决方案,是其成为主流数据库的基础。
(一)数据管理基础
1. 支持结构化数据存储,通过表、行、列的形式组织数据,遵循关系模型(实体-关系模型),确保数据之间的逻辑关联和完整性,适配各类结构化业务场景(如订单、用户、商品等数据管理)。
2. 提供完善的数据定义语言(DDL)和数据操纵语言(DML)进行数据操作,同时全面兼容标准SQL-92/99/2003,扩展支持存储过程、触发器、视图、事件调度器,满足复杂业务的逻辑实现需求:
3. 采用插件式多存储引擎架构,支持 InnoDB、MyISAM、Memory、CSV、Archive 等多种引擎,用户可根据业务场景灵活选择,不同引擎可在同一实例、同一数据库中混用,兼顾场景适配性和灵活性。
4. 事务处理能力完善,基于 InnoDB 引擎实现 ACID 特性,同时支持 SAVEPOINT 保存点(可实现事务部分回滚)、XA 分布式事务,适配单库事务和分布式系统中的跨库事务场景,尤其适用于金融、支付、订单等对数据一致性要求极高的核心业务。
5. 并发控制机制成熟,采用 MVCC 多版本并发控制,支持 READ COMMITTED(读已提交)、REPEATABLE READ(可重复读,MySQL 默认)等隔离级别,有效避免脏读、不可重复读、幻读等并发问题,平衡并发性能与数据一致性。
(二)高可用与扩展
1. 支持多种复制机制,满足不同场景的高可用需求:主从复制提供异步、半同步、组复制(Group Replication)三种模式,主库将数据变更同步到从库,从库可承担读请求或作为备份节点,主库故障时可快速切换实现故障转移;组复制基于分布式共识协议,多节点可同时处理写请求,具备自动故障检测和恢复能力。
2. 提供多种集群方案,适配不同规模的业务需求:InnoDB Cluster是官方推荐集群方案,基于组复制实现,部署管理便捷;NDB Cluster面向高并发、高可用的分布式场景,适合海量数据;Galera Cluster基于同步复制,支持多主写入,数据实时同步无延迟。
3. 支持分区表功能,可根据业务需求选择 RANGE(范围分区)、LIST(列表分区)、HASH(哈希分区)、KEY(键分区)及子分区,将大表拆分為多个小表,减少单表数据量,提升查询和维护效率。
4. 支持读写分离,可通过 Proxy 中间件(如 MySQL Proxy、MaxScale)或应用层实现,将读请求分发到从库,写请求集中到主库,实现负载均衡,提升系统并发处理能力。
(三)性能优化特性
1. 内存优化机制完善:包含Buffer Pool(核心内存缓存,缓存热点数据页和索引页,减少磁盘I/O)、自适应哈希索引(InnoDB自动为热点页构建内存哈希索引,实现O(1)快速查找);需说明MySQL 8.0已移除查询缓存,避免误导。
2. 查询优化机制丰富,大幅提升复杂查询效率:支持索引下推(ICP,将过滤条件下推到存储引擎,减少回表次数)、多范围读优化(MRR,将分散I/O转为顺序I/O)、批量键访问(BKA,优化多表连接,减少I/O开销)。
3. 并行处理能力提升:支持并行复制(从库并行应用主库binlog,减少复制延迟)、并行查询(MySQL 8.0新增,利用多CPU核心提升复杂查询速度),同时通过直方图统计,帮助查询优化器精准估算执行成本,选择最优计划。
(四)安全与生态
1. 全方位安全防护机制:支持SSL/TLS加密传输(防止网络数据窃取篡改)、静态数据加密(表空间加密,保障磁盘数据安全);提供审计日志(记录所有数据库操作,便于追溯排查);采用RBAC角色权限管理,实现细粒度权限控制,遵循最小权限原则。
2. 数据类型与存储扩展:MySQL 5.7+原生支持JSON数据类型与相关函数,适配半结构化数据场景;提供MySQL Document Store文档存储功能,兼顾关系型与非关系型数据存储需求,支持JSON文档的增删改查。
3. 特色功能支持:内置GIS空间数据支持,可存储和查询地理空间数据,实现附近地点、范围筛选等地理相关查询;InnoDB和MyISAM引擎均支持全文索引,基于倒排索引实现文本快速检索,可自定义分词规则和词项权重。
二、核心架构体系
MySQL 的核心特性(高性能、高可靠、高并发),依赖于其清晰的分层架构和高效的底层子系统,各模块协同工作,确保系统稳定、高效运行。其整体采用分层架构,核心分为连接层、服务层、存储引擎层,各层职责清晰、解耦高效,同时包含多个核心子系统,支撑各项功能的实现。
(一)整体架构层次
1. 连接层(Client/Connector):MySQL 对外的“入口网关”,负责处理客户端连接请求,进行身份认证、权限校验,管理连接线程和连接池,支持 SSL 加密连接,同时实现连接复用、超时控制、流量控制等功能,确保客户端请求安全、高效接入。
2. 服务层(Server Layer):MySQL 的核心层,与存储引擎无关,负责 SQL 语句的解析、优化、执行和日志管理,包含 SQL 接口、解析器、预处理器、查询优化器、执行器、日志模块(Binlog)等组件,决定了 MySQL“怎么理解并执行 SQL”。
3. 存储引擎层(Storage Engine Layer):负责数据的物理存储和检索,通过统一的 Handler API 与服务层交互,采用插件式架构,支持多种存储引擎,不同引擎实现事务、锁、索引等核心功能,适配不同业务场景,其中 InnoDB 是生产环境的默认引擎。
(二)核心子系统架构
1. 存储引擎子系统:核心组件为 InnoDB 存储引擎,关键技术包括聚簇索引、Buffer Pool、Change Buffer、Adaptive Hash Index、Double Write Buffer,负责数据的物理存储和检索,通过核心组件提升读写性能,依托关键技术保障数据可靠性。
2. 事务系统:核心组件是 Undo/Redo 日志,关键技术有 WAL(Write-Ahead Logging)、LSN(日志序列号)、Checkpoint 机制,基于 Undo/Redo 日志实现事务 ACID 特性,通过 WAL 确保持久性,借助 LSN 和 Checkpoint 实现故障恢复与日志管理。
3. 锁系统:核心组件为行级锁、表级锁,关键技术包含意向锁(IS/IX)、记录锁(Record Lock)、间隙锁(Gap Lock)、临键锁(Next-Key Lock),提供多粒度锁,解决并发写冲突和幻读问题,保障事务隔离性。
4. 日志系统:核心组件是 Binlog/Redo/Undo,关键技术为逻辑日志(Binlog,STATEMENT/ROW/MIXED)、物理日志(Redo)、回滚日志(Undo),三者协同工作,分别用于主从复制、崩溃恢复、事务回滚,保障数据安全和高可用。
5. 复制架构子系统:核心组件为 Master-Slave,关键技术包括 Dump Thread / I/O Thread / SQL Thread、GTID、Relay Log,基于 Master-Slave 架构实现数据同步,通过 GTID 简化故障转移,依托三类线程完成日志传输与应用。
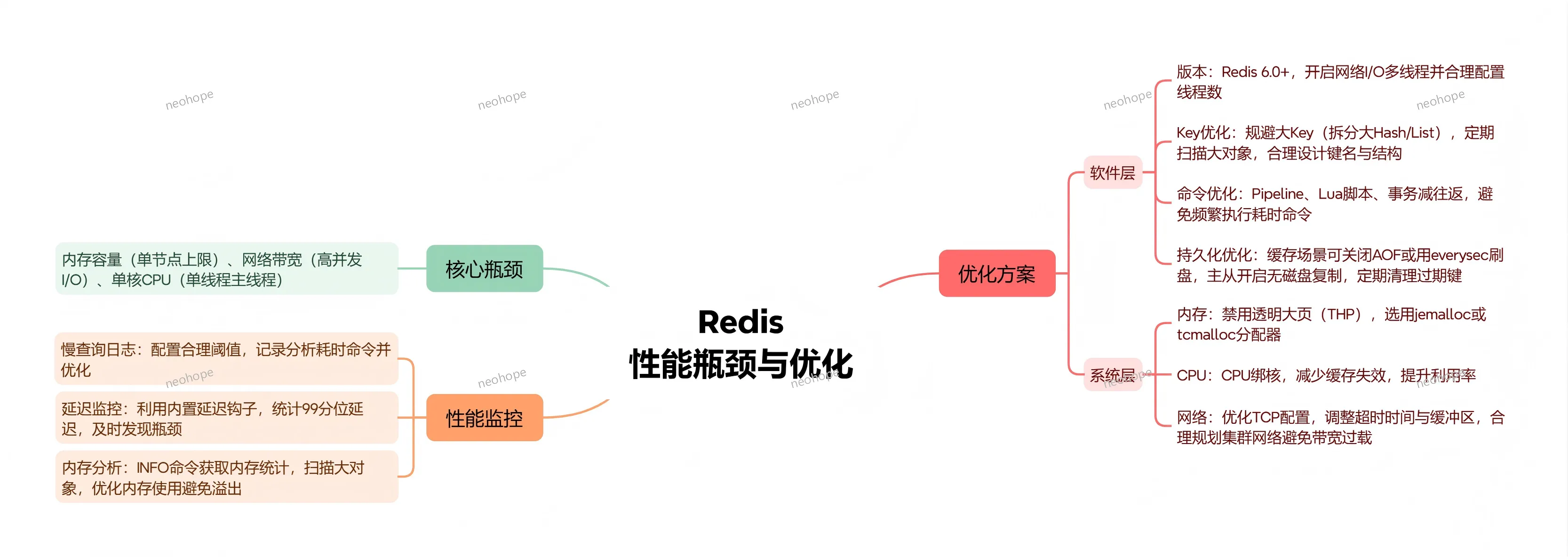
三、核心算法与数据结构
MySQL 的高性能、高并发、高可靠性,离不开底层高效的算法和数据结构,这些算法和结构贯穿于索引、事务、查询优化、存储缓存等各个核心模块,是 MySQL 核心能力的底层支撑。
(一)索引与存储结构
1. B+树索引:采用 B+ Tree(变种)算法/数据结构,核心特点是聚簇索引(数据即索引)、二级索引(叶子存 PK),通过页分裂/合并机制维护结构,填充因子默认 15/16,树高极低,大幅减少磁盘 I/O 次数,是 MySQL 最核心、最常用的索引算法。
2. 自适应哈希:基于 Hash Table 实现,由 InnoDB 引擎自动识别热点数据页并构建内存哈希索引,实现 O(1) 快速查找,无需人工配置,可显著提升热点数据查询速度。
3. 空间索引:采用 R-Tree 数据结构,专门用于 GIS 地理空间数据的存储和查询,支持二维空间索引,可高效处理地理坐标相关查询(如距离计算、范围筛选)。
4. 全文索引:基于倒排索引(Inverted Index)算法,通过 FTS_DOC_ID 标识文档,利用辅助表存储词项与文档的映射关系,支持文本关键词匹配、模糊搜索,可自定义分词规则和词项权重。
(二)事务与并发控制算法
1. MVCC(多版本并发控制):核心算法为版本链 + ReadView,每行数据隐藏 DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID 三个字段,通过 DB_ROLL_PTR 串联形成版本链,ReadView 判定事务可见版本,实现非阻塞读,提升并发性能。
2. 锁算法:采用 2PL(两阶段锁)协议,分为加锁、执行、解锁三个阶段,严格遵循协议可保证事务可串行化隔离级别,避免并发冲突。
3. 死锁检测:基于等待图(Wait-for Graph)算法,通过深度优先搜索检测死锁(循环等待),选择 Undo 量最小的事务回滚,避免系统卡死,可通过参数设置等待超时时间。
4. 事务恢复:基于 ARIES 算法,分为分析、Redo、Undo 三阶段,通过 LSN 日志序列号实现链式恢复,借助 CLR(补偿日志记录)确保故障后数据完整恢复,保障事务持久性和一致性。
(三)查询优化算法
1. 查询重写模块:采用常量折叠、子查询优化、视图合并等技术,将原始 SQL 转换为等价高效形式,减少不必要的计算和查询操作。
2. 代价模型模块:基于代价的优化(CBO)算法,通过收集表的统计信息(Cardinality、选择性),估算不同执行计划的 IO/CPU 成本,选择最优执行计划。
3. 连接优化模块:运用动态规划(DP)、贪心算法,枚举表连接顺序,优先选择 Left-deep/ Bushy tree 结构,减少连接数据量,提升多表连接效率。
4. 索引选择模块:通过索引交集/并集、索引下推(ICP)技术,实现多索引联合扫描,减少回表次数,降低查询开销。
5. 执行算法模块:提供 Nested Loop Join(小表驱动,适用于小数据量)、Hash Join(8.0 新增,适用于大数据量)、Sort-Merge Join(适用于有序数据)三种算法,根据场景自动选择。
(四)存储与缓存算法
1. Buffer Pool 组件:采用 LRU 变种(Midpoint Insertion)算法,新页插入 LRU 列表 5/8 处,分为 Old/New 子列表,避免全表扫描污染热数据,提升缓存命中率。
2. 页刷新组件:采用自适应刷新(Adaptive Flushing)算法,根据 Redo 产生速度和磁盘能力,动态调整脏页刷盘速率,平衡系统性能和数据持久性。
3. Change Buffer 组件:采用合并算法(Merge),缓冲非唯一二级索引的插入/删除操作,将随机 I/O 转换为顺序 I/O,批量合并提升写入性能。
4. 预读组件:支持线性预读(顺序扫描预读相邻区)和随机预读(基于访问模式预测),提前加载数据页,减少磁盘 I/O 次数。
(五)复制与一致性算法
1. 主从同步机制:基于 Binlog 的事件流算法/协议,主库通过 Dump Thread 发送 Binlog 事件,从库通过 I/O Thread 接收写入 Relay Log,再通过 SQL Thread 应用日志实现同步,支持异步/半同步(AFTER_COMMIT/AFTER_SYNC)模式。
2. 组复制机制:基于 Paxos 变种(Mencius/XCom)协议,实现分布式一致性,多数派节点确认后事务提交,具备自动故障检测和恢复、多主复制能力。
3. GTID 机制:采用全局事务标识符(UUID:Sequence 号),精确追踪事务来源,简化主从切换(Failover)过程,提升复制可靠性和可维护性。
四、关键机制速查
(一)InnoDB 物理结构
表空间(Tablespace)
├── 段(Segment):数据段/索引段/回滚段
│ └── 区(Extent):64个页(1MB,默认页16KB)
│ └── 页(Page):数据页/Undo页/系统页/事务数据页等
│ └── 行(Row):Compact/Dynamic/Compressed格式
InnoDB 的物理存储结构从大到小分为表空间、段、区、页、行五个层级:表空间是最高层级,包含所有数据和索引;段分为数据段、索引段、回滚段,用于区分不同类型的数据;区由 64 个页组成(默认页大小 16KB,因此每个区大小为 1MB),是磁盘 I/O 的基本单位;页是 InnoDB 存储的最小单位,包含数据页、Undo 页、系统页等多种类型;行是数据存储的最小逻辑单位,支持 Compact、Dynamic、Compressed 三种存储格式,用于优化数据存储效率。
(二)核心线程模型
1. Master Thread:InnoDB 的核心后台线程,负责调度脏页刷新、Change Buffer 合并、Undo 日志清理(purge)等后台任务,确保系统正常运行。
2. IO Thread:分为读线程(read thread)和写线程(write thread),负责处理磁盘 I/O 操作,默认各 4 个,可通过参数调整数量,提升 I/O 处理能力。
3. Purge Thread:专门负责清理已提交事务的 Undo 日志历史版本,释放磁盘空间,MySQL 5.7+ 版本中可配置多个 Purge Thread,提升清理效率。
4. Page Cleaner Thread:负责脏页刷盘操作,MySQL 5.7+ 版本中从 Master Thread 分离出来,独立调度脏页刷新,避免影响 Master Thread 的正常工作,提升系统性能。
(三)关键性能参数映射
1. innodb_buffer_pool_size:控制 Buffer Pool 大小,影响缓存命中率和查询性能,建议设置为物理内存的 50%~70%,对应 Buffer Pool LRU 管理机制。
2. innodb_log_file_size:控制 Redo 日志文件大小,影响日志循环写和 Checkpoint 频率,设置需平衡故障恢复时间和刷盘频率。
3. innodb_flush_log_at_trx_commit:控制 WAL 持久化策略(0/1/2),1 最安全(事务提交立即刷盘),0 依赖 OS 刷新,2 兼顾性能与安全。
4. innodb_lock_wait_timeout:设置死锁等待超时时间(默认 50 秒),超时后自动回滚事务,避免系统卡死,对应死锁等待超时检测机制。
5. optimizer_switch:控制查询优化器各算法(MRR/BKA/ICP 等)的开关,可根据业务场景调整,优化查询性能。
五、演进里程碑
1. MySQL 5.5 版本:核心架构变革为 InnoDB 成为默认引擎,引入半同步复制,确立 InnoDB 核心地位,提升事务可靠性。
2. MySQL 5.6 版本:新增 GTID、多线程复制(库级并行)、Online DDL、Buffer Pool 多实例,简化复制管理,提升复制和维护性能。
3. MySQL 5.7 版本:新增原生 JSON、Group Replication、多线程复制(事务级并行)、虚拟列,适配半结构化数据和分布式高可用场景。
4. MySQL 8.0 版本:实现数据字典事务化(InnoDB 存储),新增窗口函数、CTE、Hash Join、降序索引等,进一步提升查询性能和系统可靠性。
六、总结
MySQL 之所以能成为全球最流行的开源关系型数据库,核心在于其“灵活架构 + 高效算法 + 易用设计”的组合:插件式存储引擎架构带来了极强的场景适配能力,InnoDB 引擎通过 MVCC+WAL+B+树构建的高性能事务处理能力,支撑了其核心竞争力;其算法设计平衡了理论严谨性(ACID、2PL、ARIES)与工程实用性(自适应算法、多线程并行),覆盖索引、事务、查询优化、存储缓存、复制等各个核心模块。
从核心功能与特性来看,MySQL 覆盖数据管理、高可用、性能优化、安全生态等全场景需求;从架构体系来看,清晰的分层架构和完善的核心子系统,确保了系统的稳定性和可扩展性;从底层算法来看,高效的数据结构和算法,支撑了高性能、高并发、高可靠的核心能力。无论是中小团队的初创项目,还是大型企业的核心业务系统,MySQL 都能通过自身的功能和特性,适配不同的业务需求,成为数据存储和管理的首选方案。
如果觉得这篇文章对你有帮助,欢迎点赞、收藏,也可以在评论区留言,聊聊你在使用MySQL时遇到的问题~