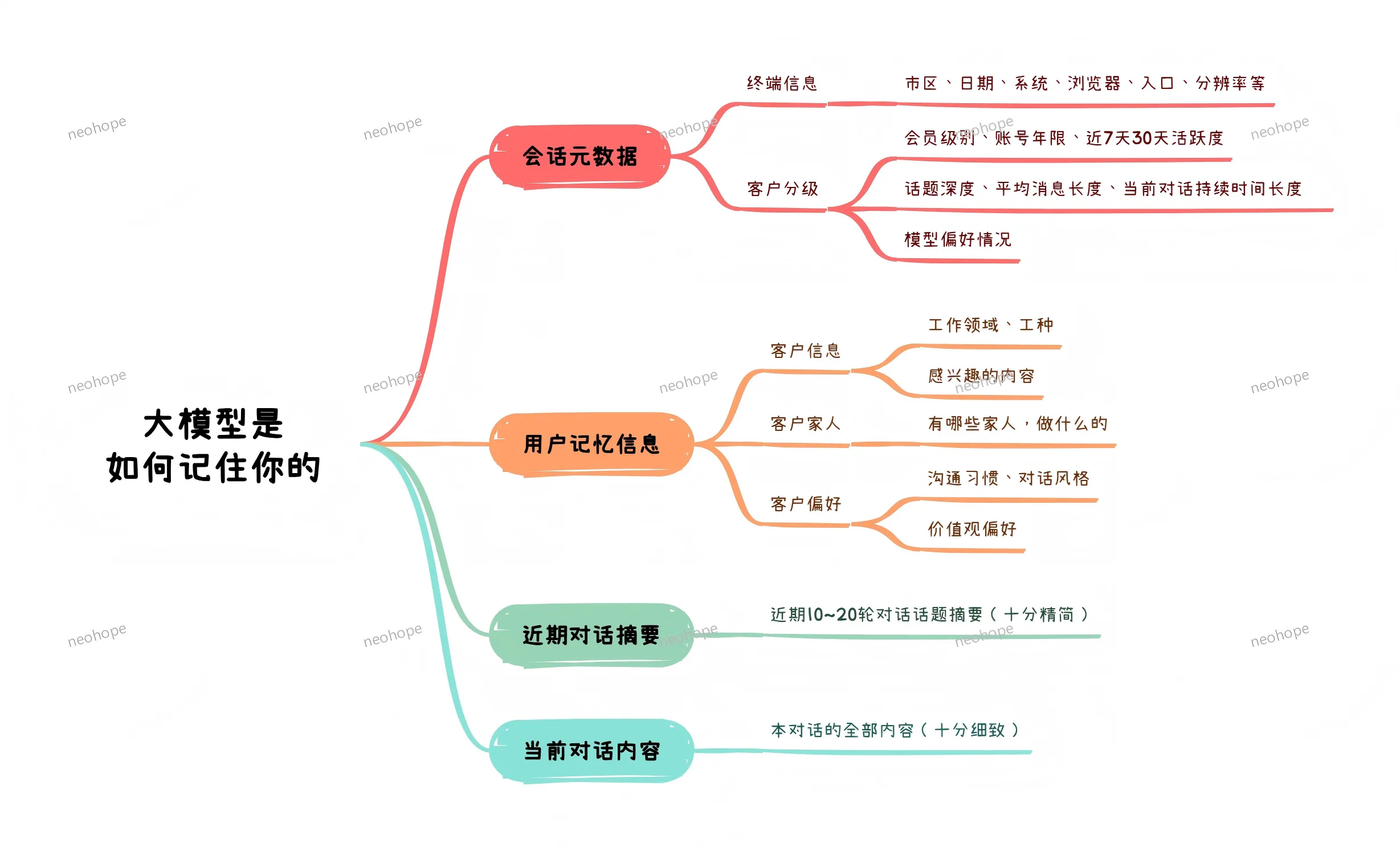
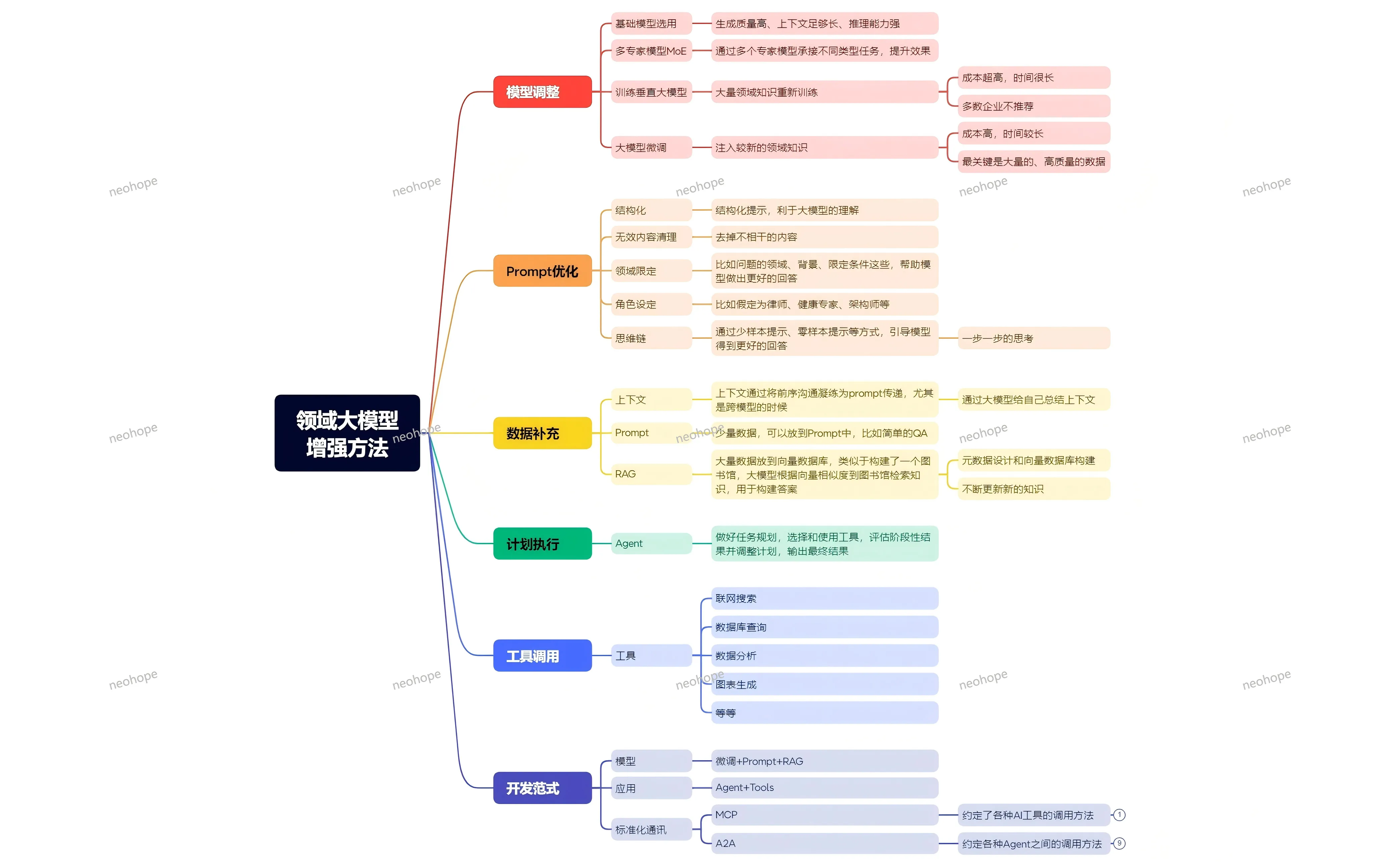
咨询了一下各大模型,大模型时代碳基生物核心能力:
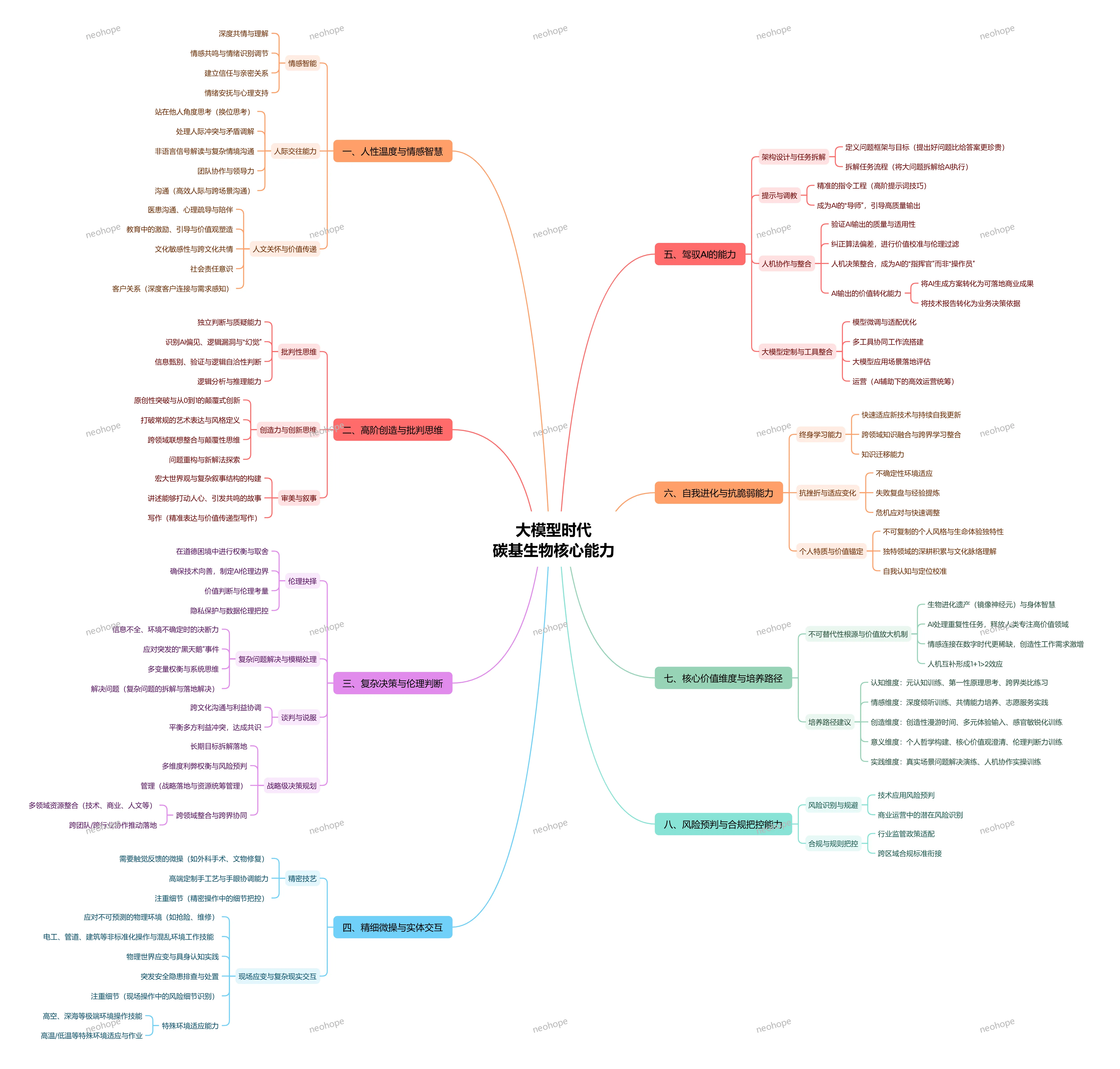
大模型时代,人类的核心竞争力:7 种不可替代的 “碳基生物能力”
当 AI 能写文案、做分析、解难题,甚至替代部分重复性工作时,很多人开始焦虑:“人类的价值在哪里?” 其实答案很明确 —— 大模型能高效处理 “标准化任务”,但人类独有的 “情感温度、创造性思维、复杂决策力” 等核心能力,才是不可替代的立身之本。今天就拆解大模型时代,人类最该深耕的 7 种 “碳基生物核心能力”,帮你找准竞争力锚点。
一、人性温度与情感智慧:AI 无法复制的 “情感连接力”
机器能识别情绪,但永远无法真正 “共情”;能输出安慰的话术,却没有发自内心的人文关怀 —— 这正是人类的核心优势:
深度共情与理解:能站在他人角度思考问题,读懂语言背后的情绪、委屈与期待,比如医患沟通中安抚患者焦虑,心理咨询中感知隐性需求;
情感调节与关系构建:不仅能识别情绪,还能调节氛围、化解人际冲突,建立信任与亲密关系,比如团队管理中的激励引导、跨部门协作中的矛盾调解;
文化敏感与价值传递:理解不同文化背景的差异,兼顾人文关怀与价值观引导,比如教育中塑造孩子的正向品格,跨文化沟通中避免误解。
这种 “有温度的连接”,是 AI 再精准的算法也无法复刻的,也是人际关系、客户服务、教育医疗等领域的核心需求。
二、复杂决策与伦理判断:不确定性中的 “价值锚点”
大模型能提供数据支持和方案选项,但面对模糊地带、多方利益冲突时,最终的决策力仍属于人类:
模糊问题处理与决断:在信息不全、环境不确定的情况下,能权衡多变量利弊,做出合理决断,比如商业运营中应对突发市场变化,危机事件中的快速响应;
伦理权衡与价值校准:在道德困境中坚守底线,纠正 AI 的算法偏差,确保技术向善,比如处理用户数据时的隐私保护,面对利益诱惑时的合规把控;
长期战略与风险预判:能拆解长期目标、整合多领域资源,预判潜在风险,比如企业战略规划中的跨界协同,项目推进中的风险规避。
这种 “在不确定中找确定” 的决策能力,以及基于价值观的伦理判断,是人类作为 “决策者” 而非 “操作员” 的核心价值。
三、精细微操与实体交互:物理世界的 “实践掌控力”
AI 擅长虚拟场景的信息处理,但面对需要物理接触、现场应变的场景,人类的 “具身认知” 优势尽显:
精密技艺与细节把控:比如外科手术中的精准操作、文物修复的细致打磨、高端手工艺的个性化创作,需要触觉反馈与手眼协调的高度配合;
复杂环境适应与应变:能在高空、深海、高温等极端环境作业,或应对建筑维修、抢险救灾等非标准化场景,快速处理突发安全隐患;
实体世界的互动感知:通过身体感官感知物理环境的细微变化,比如电工排查线路故障、工程师调试设备,这种 “沉浸式实践” 是 AI 目前无法替代的。
四、创造力与创新思维:从0到1的 “颠覆式突破”
大模型能整合现有信息生成内容,但无法拥有 “打破常规、创造新价值” 的原创力:
颠覆性思维与跨域整合:能打破行业边界,将不同领域的知识联想融合,比如将科技与艺术结合创造新的表达形式,将商业模式与公益理念结合开辟新赛道;
原创表达与故事叙事:能构建宏大的世界观,讲述打动人心的故事,比如作家的文学创作、设计师的风格定义、品牌的情感化叙事;
问题重构与新解法探索:不局限于现有答案,而是重构问题框架,找到从 0 到 1 的创新方案,比如创业中的模式创新、科研中的技术突破。
这种 “无中生有” 的创造力,是推动社会进步的核心动力,也是 AI 难以企及的领域。
五、驾驭AI的能力:人机协作的 “指挥官思维”
未来的核心竞争力,不是 “对抗 AI”,而是 “用好 AI”—— 成为 AI 的 “导师” 和 “指挥官”:
精准指令工程与引导:掌握高阶提示词技巧,能清晰定义问题框架,引导 AI 输出高质量结果,而不是被动接受 AI 的默认答案;
AI输出的验证与转化:能判断 AI 内容的逻辑自治性,识别偏见与 “幻觉”,并将技术报告、AI 生成方案转化为可落地的商业成果;
工具整合与定制优化:能搭建多工具协同工作流,根据场景微调模型,让 AI 成为适配自身需求的 “专属助手”,比如运营中的高效统筹、工作中的流程优化。
这种 “人机协同” 的能力,能让 AI 成为释放人类精力的 “杠杆”,聚焦更高价值的工作。
六、自我进化与抗脆弱能力:终身成长的 “适应力”
大模型的迭代速度惊人,但人类的 “自我更新” 能力才是长期竞争力的关键:
终身学习与知识迁移:能快速适应新技术、跨领域学习,将所学知识灵活运用到新场景,比如从传统行业转型 AI 相关领域,将职场经验迁移到创业项目;
抗挫折与复盘优化:能从失败中提炼经验,在变化中快速调整,比如项目失利后的复盘改进、行业变革中的转型适应;
自我认知与定位校准:能清晰认识自身优势,校准个人价值定位,在人机互补的生态中找到不可替代的角色,比如深耕细分领域形成专业壁垒。
七、核心价值维度:不可复制的 “个人特质与生命体验”
每个人的独特经历、文化脉络、价值取向,构成了独一无二的 “个人品牌”,这也是不可替代的根源:
独特生命体验与风格:比如长期积累的行业洞察、个人化的表达风格、融入生命体验的创作灵感,这些都是 AI 无法模仿的;
多元价值与文化理解:对特定领域的深度积累、对文化脉络的精准把握,比如非遗传承人的文化坚守、行业专家的经验沉淀;
社会责任与人文担当:在追求个人价值的同时,兼顾社会价值,比如推动技术向善、参与公益事业,这种 “有温度的价值追求” 让人类的存在更有意义。
总结:大模型时代的 “生存逻辑”—— 人机互补,放大优势
大模型的出现,不是为了替代人类,而是为了让人类从重复性、标准化的工作中解放出来,聚焦更有价值的核心能力。未来的竞争,不再是 “谁做得快”,而是 “谁做得有温度、有深度、有创意”。
与其焦虑 AI 的冲击,不如深耕这些 “碳基生物核心能力”:用情感智慧建立连接,用创新思维创造价值,用决策能力掌控方向,用协作思维驾驭 AI。当人类的 “独特性” 与 AI 的 “高效性” 形成互补,就能实现 1+1>2 的效应,在大模型时代站稳脚跟。
你觉得自己最核心的 “不可替代能力” 是什么?在人机协作中,你有哪些实用技巧?欢迎在评论区留言交流~