Prompt KV Cache是如何实现的
如果你是大模型API的重度用户,看着token快速燃烧,大概率会思考过这样一个问题:
每次和大模型对话,都会先有几百个token的固定system prompt(角色设定、工具定义、甚至是一整份文档),然后才是几十个token用户的问题。但我们却要为这段固定不变的system prompt反复付费、反复等它算完。这是一种巨大的浪费,不能想想办法节约一些token吗?
Prompt KV Cache要解决的就是这件事:让完全相同的prompt前缀不要重复计算,可以在后续的对话中,继续复用已经计算好的结果。本文来剖析一下,这个技术是如何实现的。
一、痛点:长prompt为啥贵?不在生成,在prefill
prompt明明是我们给大模型的,凭啥收费,而且凭啥越长越贵?
其实,大模型生成token的流程分两段:
1、Prefill阶段:把整段输入(system + 用户消息 + 工具定义……)从左到右扫一遍,把每个 token 在每一层算出一个Q,一个K和一个V张量(Q不再用于后续计算,但K和V会)。这部分是纯矩阵运算,输入越长越吃算力。
2、Decode阶段:每个新token也要计算Q、K、V,这个过程中,需要查询本次prompt前序token的所有K,加权读V,然后进入前馈网络,最终往外输出概率最高的下一个token;
为了让大模型理解问题,记住前序聊天内容,大家通常都会给Prompt塞一堆预设内容,最后才是我们的问题。真正烧钱的,往往不是「输出那几十个字的decode」,而是「每次请求都把几百上千个固定token的KV从头算一遍」。
所以Prompt KV Cache要解决的问题非常朴素:如果两次请求的前面1000个token完全一样,那1000个token对所有层的KV能不能只算一次?
二、原理:KV到底是什么,为什么能缓存
Transformer计算每一层的自注意力(Self-Attention)时,每个token都需要乘以三个训练好的矩阵,从而得到Q、K、V张量:
Q = x @ W_Q
K = x @ W_K
V = x @ W_V
Q、K、V看起来有些枯燥,我们简化一下,把这个过程类比为一次图书馆检索:
| 矩阵 | 全称 | 直觉含义 | 类比 |
| Q (Query) | 查询 | “我在找什么?” | 你手中的搜索词 |
| K (Key) | 键 | “我能提供什么?” | 图书馆每本书的索引标签 |
| V (Value) | 值 | “我实际包含什么内容?” | 书的实际内容 |
然后计算Attention:
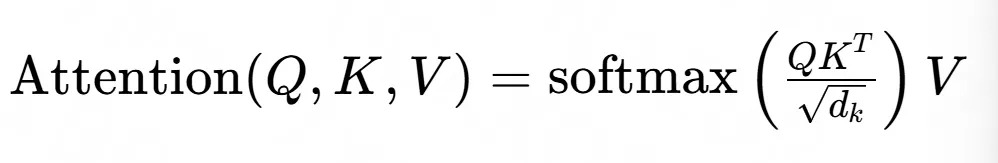
(Attention的计算有些小复杂,后面会举个例子)
如果不细看,好像都是矩阵运算,貌似没有什么操作空间?
但这些运算有个特点,每个token只知道它自己和之前的token,并不知道之后的token。以单个token为视角,操作空间就出现了。参考上面的公式,在同一次请求中,生成第N个token时,它需要Q去点乘 K₁…Kₙ,再加权求和 V₁…Vₙ,看起来是这样的:
生成第1个token → 计算 K1, V1(缓存)
生成第2个token → 只计算 Q2, K2, V2,复用缓存的 K1, V1
生成第3个token → 只计算 Q3, K3, V3,复用缓存的 K1,V1,K2,V2
...
对不同请求,在请求的前1~N个token完全一致的情况下,由于参与运算的参数都是一样的,所以计算出来的K₁…Kₙ 和 V₁…Vₙ是一致的。如果第一次计算后,把计算结果缓存下,后续构造prompt时保持前面的prompt不变,那就只需计算最后不同的一小部分即可,恭喜你省token了:
请求A: [System Prompt (2000 tokens)] + [用户问题A (50 tokens)] # Prefill需计算2050个token
请求B: [System Prompt (2000 tokens)] + [用户问题B (30 tokens)] # Prefill只计算30个token
请求C: [System Prompt (2000 tokens)] + [用户问题C (80 tokens)] # Prefill只计算80个token
聪明的你一定已经发现:对于单次请求,已经默认做了KV Cache(计算token10的时候,token1~token9的结果都在)。所以Prompt KV Cache要做的事就具象为——让KV Cache跨请求存活,不能用一次就被释放,并且能被”相同前缀”的请求复用。
三、复用:Prompt KV Cache
既然相同的Prompt序列,可以得到相同的KV。那要解决的问题就变成了,Prompt KV Cache用什结构存、如何快速检索?两种比较直观的方式是hash链和基数树,我们接下来讲一下hash链的存储与检索(基数树大同小异)。
3.1 KV分块(Paged KV Cache)
GPU显存宝贵,不可能一次分配一大块显存然后永远不释放(碎片化、OOM)。主流方案是把KV按固定大小分块(block),比如每块存16个token的KV:
Block 0: token 0~15
Block 1: token 16~31
Block 2: token 32~47
...
每个请求的token们,就被按16个一组进行了分组,每组都保存了对应promot前缀的KV组合,最终组成了一个叫做block table的指针数组。接下来,咱们看下这些block是如何相互绑定的。
3.2 Chained Hash:前缀绑定
每个block有一个 hash key,而且是链式的(有点儿区块链的意思):
key(block_i) = hash( key(block_{i-1}) || tokens_in_this_block )
为什么要链式hash?如果两个不同的prompt,碰巧最后一个 block 的 token 序列撞车了(比如结尾都是标点),但前面语义完全不同 → KV 绝对不能复用。所以即使block内容一样,但他们前序block不一样,hash就不能一样。
如果用了链式hash呢?前面任何一个token变了,后面所有block的hash全变,天然免疫”尾部假命中”。
这样,最终就维护一个全局哈希表:
hash_key → (physical_block_address, ref_count, layer_KV_ptrs)
3.3 新请求来了:逐块获取缓存
假设新请求的 token 序列是 t₁…tₙ。
- 把token序列,按指定大小拆分为blok
- 从block1开始,算它的chain-key
- 去全局表查:
- HIT → ref_count += 1,把该物理块挂到新请求的block table(零拷贝,只改个指针地址)
- MISS → 分配新物理块,执行真正的prefill算KV,算完塞进全局表
- 继续下一个block,直到第一个MISS之后的所有block都只能MISS,继续计算KV(因为前缀断了)
请求A: [System Prompt 800t] + queryA → 全量计算,KV blocks写入全局表
请求B: [System Prompt 800t] + queryB → system prompt对应的blocks全HIT,只计算queryB的部分
这就是所谓 exact token-level prefix match:从第 1 个 token 开始比,第一次不一致就把前缀截断,之前的复用,之后全重算。
3.4 释放与淘汰
- 请求结束 → 遍历自己的 block table → ref_count-=1
- ref_count==0 → block可被回收(LRU/显存压力触发驱逐)
实际落地的时候,涉及到多租户的隔离,单租户也涉及到物理设备隔离,还涉及TP group的划分。所以路由机制要保证,把相同前缀请求路由到同一物理设备,同一TP组,才有可能用到Prompt KV Cache。
四、如何构建Prompt
根据上面的内容,大家可以知道Prompt KV Cache可以复用的前提是”从第1个token开始逐token完全一致才能复用”。给我们的启示就是:
1、不能用中转站
2、APP key要保持不变
3、静态内容全顶到最前面,不许做任何变化;动态内容全压到最后面
五、举个例子
1、初始场景
约定:
这就是个示例,简化了很多内容,和实际情况有很大差距,咱们不发论文,别较真。
token划分:1个字符,当做1个token
block划分:4个token,是1个block
模型分层:共4层(L1~L4),无限简化
我们的计数不从0开始,从1开始
第一次请求:我爱吃苹果一天吃一个。
第二次请求:我爱吃苹果真好吃!
2、初始情况
已缓存第一次请求的全部内容:“我爱吃苹果一天吃一个。”
这11个token,被划分为3个block,这些block所有层的KV都已缓存在KV Cache里。由于第2、3个block后续用不到,我们只看block1。
前4个token[我(1), 爱(2), 吃(3), 苹(4)]的KV被打包成block1,chain_hash=H1,refcnt=1,挂在block_hash表里:
Block1: tokens[1..4] = "我爱吃苹"
L1: K1_1..K1_4, V1_1..V1_4
L2: K2_1..K2_4, V2_1..V2_4
L3: K3_1..K3_4, V3_1..V3_4
L4: K4_1..K4_4, V4_1..V4_4
3、第二次请求来了
新prompt共10个token,前4个跟缓存完全一致:
位置: 1 2 3 4 5 6 7 8 9 10
token:我 爱 吃 苹 果 真 好 吃 ! <eos>
↑─────────────────↑ ↑──────────────────────────↑
命中区(4个) 新算区(6个: 5~10)
注意block1是完全一致的,但block2的第二个token已经不一致了,所以block2就开始分叉了。
4、Step 1:Prefix检测
engine收到请求,tokenizer得到[1,2,3,4,5,6,7,8,9,10],开始逐block进行hash:
block1: tokens[1..4] = "我爱吃苹"
chain_key = hash(prev=None || "我爱吃苹") = H1
查 block_hash 表:
H1 → block1 (phys_addr, refcnt=1) ✅ HIT
block2: tokens[5..8] = "果真好吃的"[注1]
prev_key = H1
chain_key = hash(H1 || "果真好吃")
查表:❌ MISS → 分配新物理块 block2_new
于是,新请求的block table变成了这样:
新请求 block_table = [
Block1 (引用, refcnt 变成 2), ← 零拷贝,只改了个指针
Block2_new (新分配, 待算), ← 5~8
Block3_tail (新分配, 待算) ← 9~10
]
这样,就把block1对应的运算,全部省下来了。
5、Step 2:Prefill 新token(5~10)
对这6个新token,引擎要做一次批量 prefill(batch_size=6, seq_len=6,但每个要attend到历史):
5.1 算这6个token自己的QKV
由于每个token只能看到自己和之前的token,所以:
token5 看: {1,2,3,4,5} ← 1~4 从缓存读K,5 是自己
token6 看: {1,2,3,4,5,6} ← 1~4 缓存,5 刚算的也在"已存在"区,6 自己
token7 看: {1..7}
...
token10看: {1..10}
每个token过每层 W_Q/W_K/W_V:
token5(果): q5_l1..q5_l4, k5_l1..k5_l4, v5_l1..v5_l4 ← 新算,写完进 block2_new
token6(真): q6..., k6..., v6...
token7(好): ...
token8(吃): ...
token9(! ): ...
token10(<eos>): ...
5.2 Attention 计算(以token5为例)
L1 层:
Q 的来源:
q5_L1 刚算出来,不会用到前4个q
K 的来源:
K1,K2,K3,K4 → 从 Block1 缓存读
K5 → 刚算的 k5_L1
K6~K10 → 对token5来说,看不到6~10,所以只用 K1~K5
V 的来源:
V1,V2,V3,V4 → 从 Block1 缓存读
V5 → 刚算的 V5_L1
V6~V10 → 对token5来说,看不到6~10,所以只用 V1~V5

再看下公式,首先计算红色部分:
scores_5 = [q5·K1, q5·K2, q5·K3, q5·K4, q5·K5, q5·K6(=-inf), ...]
↑────────── 从缓存读K ──────────↑ ↑自己↑ ↑ mask掉 ↑
scores_5除以下方常数后得到scaled_score_5;
scaled_score_5传给Softmax,得到绿色部分weight_5;
最后加权求和得到蓝色部分(用到V1~V5):
out5_l1 = Σweight_i · V_i
out5_l1经过残差连接+层归一化、前馈神经网络、残差连接+归一化,最后成为L2层的输入。
与L1同样方式,通过L2~L4,最终在L4出口得到h5(h5在这里没有用因为下一个token已知;但token10得到的h10会被用于预测下一个token)。
5.3 token6~10同理
后续token依次计算,每多计算一个block,KV缓存就多一部分(当然,存几层、存多久,和平台策略相关)
6、Step 3:Prefill结束
10 个 token 全部算完,KV Cache 现在长这样:
Block1: "我爱吃苹"(1~4) refcnt=2 ← 第一次请求+第二次请求共享
Block2_new: "果真好吃"(5~8) refcnt=1 ← 第二次请求独有
Block3_tail: "!<eos>"(9~10) refcnt=1 ← 第二次请求独有
token10走到最后,会得到h10,这样就可以预测第11个token了。
7、Step 4:进入Decode阶段
在上一步,已经得到h10了。
h10经过最终层归一化、LM Head语义向量投影、Temp缩放+概率归一化,通过采样策略,最后得到token11。
同样的,我们把h10给到L1,最终会得到h11,通过h11可以得到token12。h11给到L1可以得到h12,以此类推。
六、厂商做法
底层实现机制大同小异(hash+block复用+GPU显存/SSD分级存储),但cache管控的哲学差异较大:
| 厂商 | 怎么激活 | 门槛 | TTL | 写费 | 命中折扣 |
|---|---|---|---|---|---|
| OpenAI | 隐式自动(≥1024 tok 前缀倾向缓存) | ~1024 tok | 几分钟级 | 无 | ≈50% off |
| Anthropic | 显式 "cache_control":{"type":"ephemeral"} 断点 |
1024–4096 | 5min(1.25x写费)/ 1h(2x写费) | 有 | 90% off(读) |
| Google Gemini | CachedContent 对象 API(显式创建/引用) |
32K 起 | 你设 TTL | 不按写收费,按小时收存储费 | 显著减免 |
| DeepSeek | 隐式自动 | 64 tok(最细) | 动态几小时~天 | 无 | 90% off |
OpenAI 的体验最省心:你什么都不用标,相同长前缀有一定概率命中;代价是命中率不完全可控(实测经常 40%~70%,看负载和路由)。
Anthropic 最”外科医生”:cache_control 让你把断点精确打在 system / tools / 长文档那一级,命中率能做到稳定接近 100%,但你要付出写缓存的溢价。
Gemini 适合”一本书反复问”的企业场景(32K 起),走对象化管理模型。
DeepSeek 最有意思:门槛压到 64 token、落分布式NVMe SSD(便宜),介质成本低到敢给1折还不收写费;代价是TTL不完全承诺、冷读首字稍慢。
对于Prompt KV Cache你有什么好的建议或想法吗?欢迎分享