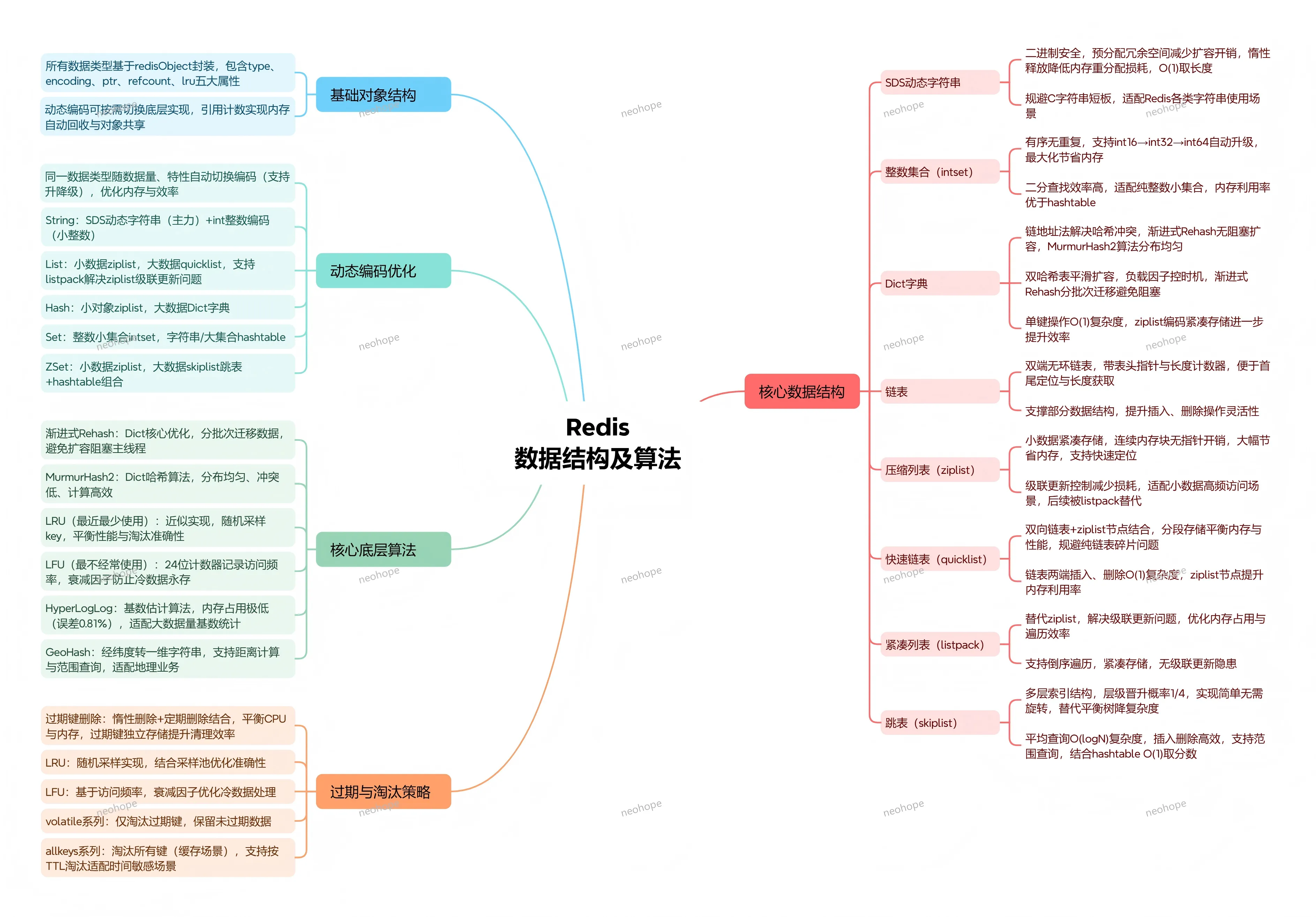
一、基础对象结构
核心对象:所有数据类型均基于redisObject统一封装,包含五大核心属性:type(数据类型)、encoding(底层编码)、ptr(数据指针)、refcount(引用计数)、lru(淘汰标识)。
设计优势:支持动态编码,可根据数据量、数据类型按需切换底层实现,兼顾性能与内存利用率;通过引用计数实现内存自动回收,支持对象共享,进一步提升内存利用率。
二、动态编码优化
核心原则:同一数据类型根据数据量、数据特性,自动切换底层编码,支持编码升级与降级,针对不同场景优化,减少内存碎片,提升算法效率。
1、String
底层采用SDS动态字符串(主力)与int整数编码(小整数场景),适配短字符串常用场景。
2、List
小数据量用压缩列表(ziplist),大数据量转快速链表(quicklist),同时支持listpack紧凑列表,解决ziplist级联更新问题。
3、Hash
小对象用ziplist,大数据量转Dict字典,平衡内存与查询性能。
4、Set
整数小集合用intset,字符串/大集合用hashtable,实现高效去重。
5、ZSet
小数据量用ziplist,大数据量用skiplist跳表+hashtable组合,兼顾排序与查询效率。
三、核心数据结构
1、SDS动态字符串
核心特性:二进制安全,支持预分配冗余空间减少扩容开销,采用惰性释放策略降低内存重分配损耗,可实现O(1)时间复杂度获取字符串长度。
优势:规避C字符串短板,适配Redis中字符串的各种使用场景(如键名、字符串值),兼顾性能与灵活性。
2、链表
底层实现:双端无环链表,带有表头指针与长度计数器,便于快速定位链表首尾节点与获取链表长度。
作用:作为部分数据结构的底层支撑,提升插入、删除操作的灵活性,适配需要频繁修改的场景。
3、Dict字典
核心机制:采用链地址法解决哈希冲突,通过渐进式Rehash实现无阻塞扩容,哈希算法选用MurmurHash2,哈希分布均匀,减少冲突概率。
优化设计:双哈希表结构实现平滑扩容,通过负载因子控制扩容时机;渐进式Rehash分批次迁移数据,结合定时任务与读写操作触发迁移,避免阻塞主线程。
性能:单键增删改查操作时间复杂度为O(1),ziplist编码场景下,因紧凑存储(CPU缓存友好,无指针开销)进一步提升效率。
4、压缩列表(ziplist)
核心设计:小数据紧凑存储,采用连续内存块组织数据,元素间无指针开销,大幅节省内存空间,支持快速定位元素。
优化:通过级联更新控制,减少级联更新带来的性能损耗,适配小数据量、高频访问的场景,后续被listpack进一步优化替代。
5、快速链表(quicklist)
核心结构:双向链表与Ziplist节点的结合,通过分段存储平衡内存占用与操作性能,避免纯链表的内存碎片问题。
性能优势:链表两端插入、删除操作时间复杂度为O(1),Ziplist节点紧凑存储提升内存利用率,兼顾灵活性与内存效率。
6、紧凑列表(listpack)
设计目的:替代ziplist,解决ziplist级联更新的性能问题,优化内存占用与遍历效率。
优势:支持倒序遍历优化,紧凑存储节省内存,无级联更新隐患,适配小数据量紧凑存储场景。
7、整数集合(intset)
核心特性:有序存储、无重复元素,支持自动升级策略(int16→int32→int64),根据元素大小动态调整存储类型,最大限度节省内存。
性能:采用二分查找算法,查询效率高,适配纯整数小集合场景,内存利用率远超hashtable。
8、跳表(skiplist)
核心结构:多层索引结构,层级随机晋升概率为1/4,实现简单(无需旋转操作),替代平衡树降低实现复杂度。
性能:平均查询时间复杂度为O(logN),插入、删除操作效率高,支持高效范围查询,结合hashtable实现O(1)时间复杂度获取元素分数,双结构兼顾排序与查询需求。
四、核心底层算法
1、渐进式Rehash
Dict字典核心优化,分批次迁移哈希表数据,结合定时任务与读写操作触发迁移,避免扩容过程中阻塞主线程,保障服务流畅。
2、MurmurHash2
Dict字典核心哈希算法,哈希分布均匀,冲突概率低,计算高效,适配Redis的哈希存储场景。
3、LRU(最近最少使用)
近似实现,通过随机采样key提升效率,作为内存淘汰策略之一,平衡性能与淘汰准确性,配合随机采样池优化淘汰效果。
4、LFU(最不经常使用)
基于访问频率实现,通过24位计数器记录元素访问频率,设置衰减因子防止冷数据永存,适配高频访问场景的内存淘汰需求。
5、HyperLogLog
基数估计算法,用于统计独立元素个数,内存占用极低,标准误差仅0.81%,无需存储全部元素,适配大数据量基数统计场景。
6、GeoHash
地理位置编码算法,将二维经纬度坐标映射到一维字符串,支持距离计算与范围查询,适配地理位置相关业务场景。
五、过期与淘汰策略
1、过期键删除
采用惰性删除与定期删除相结合的方式,平衡CPU与内存开销。惰性删除在访问键时判断是否过期,避免无用删除操作;定期删除通过随机采样删除过期键,控制删除频率,不阻塞主线程;过期键独立存储于哈希表,提升清理效率。
2、内存淘汰策略
共8种,核心分为4类,配合maxmemory配置使用,防止内存溢出:
2.1、LRU
近似算法,通过随机采样key实现,结合随机采样池优化淘汰准确性。
2.2、LFU
基于访问频率,通过24位计数器记录访问频率,设置衰减因子防止冷数据永存。
2.3、volatile系列
仅淘汰设置过期时间的键,适用于需要保留未过期数据的场景。
2.4、allkeys系列
淘汰所有键,适用于缓存场景,优先保留访问频率高的键;同时支持按TTL过期时间淘汰,适配时间敏感场景。