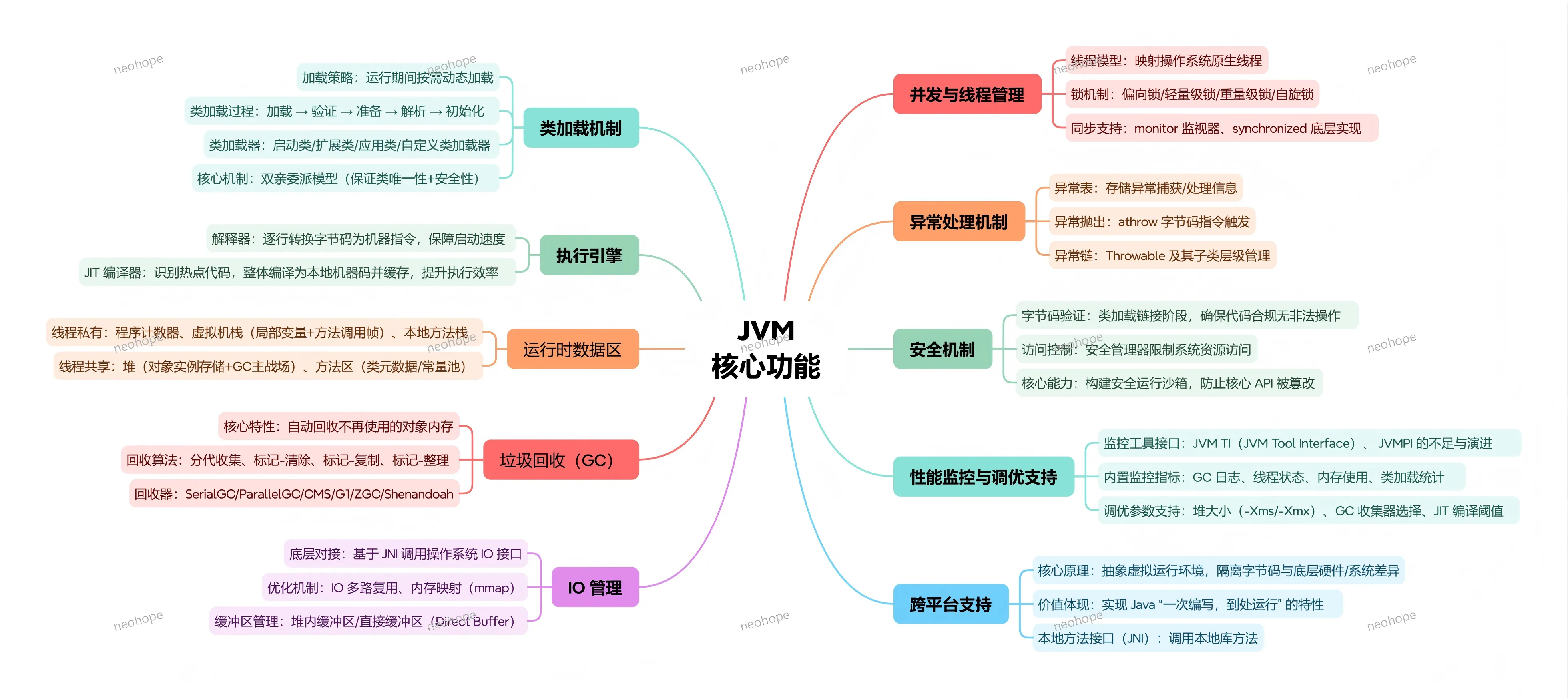
在编程领域,编译语言凭借高效的执行性能、严谨的内存控制,长期占据系统开发、底层架构、高性能服务等核心场景。C、C++ 作为经典老牌编译语言,奠定了现代编程的基础;Go、Rust 则作为后起之秀,针对新时代开发痛点(如并发安全、内存安全)进行了革新性设计。本文将从语言定位、核心特性、性能效率、内存管理、并发模型、生态场景等核心维度,对这四大主流编译语言进行全方位对比,帮你清晰认知各语言的优势与适用场景,为技术选型提供参考。
一、语言定位:各自的核心使命与设计初衷
| 维度 | C | C++ | Go | Rust |
|---|---|---|---|---|
| 设计年代 | 1972 | 1985 | 2009 | 2010 |
| 核心哲学 | 极致简洁、直接控制硬件 | 零成本抽象、向后兼容 | 简洁高效、快速编译 | 内存安全、零成本抽象 |
| 定位 | 系统编程基石 | 高性能通用系统编程 | 云原生、高并发服务 | 安全关键型系统编程 |
| 适用层级 | 操作系统、驱动、嵌入式 | 游戏引擎、高频交易、大型软件 | 微服务、DevOps工具、云基础设施 | 区块链、浏览 |
每一门语言的诞生,都对应着特定的时代需求和开发场景,定位的差异决定了它们的技术侧重和适用边界。
– C语言:诞生于1972年,核心定位是“系统级编程语言”,初衷是为了编写UNIX操作系统,追求 极致简洁、高效、可移植。它摒弃了高级语言的冗余特性,贴近硬件底层,能直接操作内存和CPU指令,是连接硬件与软件的“桥梁”,也是后续众多语言(包括C++、Go)的设计基础。
– C++:在C语言基础上于1983年诞生,定位是“兼容C的通用型编译语言”,核心目标是 在保持C语言高效性的同时,引入面向对象编程(OOP)特性,解决C语言在大型项目中代码复用、模块化不足的问题。它兼容C语言的所有语法,同时新增类、继承、多态等特性,兼顾底层控制与高层抽象。
– Go语言:由Google于2009年推出,定位是“云原生时代的高性能并发编程语言”,初衷是解决大型分布式系统中“高并发、低延迟、易维护”的痛点。它简化了语法,摒弃了复杂的OOP特性(如继承),内置并发模型,主打“简单、高效、易部署”,适配云计算、微服务等场景。
– Rust语言:由Mozilla于2010年稳定发布,定位是“安全、高效的系统级编程语言”,核心使命是 解决C/C++的内存安全问题,同时保持与C/C++相当的性能。它通过独特的所有权机制、借用规则,在编译期杜绝内存泄漏、空指针、数据竞争等问题,兼顾底层控制与安全,适配嵌入式、操作系统、区块链等对安全和性能要求极高的场景。
二、核心特性:语法与设计的关键差异
| 特性 | C | C++ | Go | Rust |
|---|---|---|---|---|
| 模块系统 | 头文件包含 | 头文件/模块(C++20) | package | module(2018 edition) |
| 可见性控制 | static关键字 | public/private等 | 首字母大小写 | pub关键字 |
| 接口抽象 | 函数指针 | 抽象类、虚函数 | interface | trait |
| 包管理 | 无标准 | 无标准(多种方案) | 内置go mod | 内置Cargo |
| 编译时检查 | 基本类型检查,无内存安全检查 | 类型检查强于C,模板元编程可在编译期计算 | 类型检查强,但1.18之前无泛型,表达能力受限 | 最强编译时检查,包括生命周期、所有权、并发安全 |
四大语言的核心特性,反映了它们的设计哲学——C追求简洁可控,C++追求兼容与灵活,Go追求简单高效,Rust追求安全与性能的平衡。
2.1 语法特性
– C语言:语法极简,无面向对象、无泛型、无垃圾回收,仅包含基本数据类型(int、char、float等)、指针、数组、函数和结构体。代码简洁紧凑,学习门槛低,但编写大型项目时需手动管理所有细节,代码复用性差。
– C++:兼容C语法,新增面向对象三大特性(封装、继承、多态),支持泛型(模板)、异常处理、命名空间、STL标准库等。语法灵活度极高,可根据需求选择“面向过程”或“面向对象”编程,但灵活性也带来了复杂度,学习门槛高,容易写出难以维护的代码。
– Go语言:语法极简,摒弃了继承、多态、泛型(早期不支持,后期新增基础泛型)、异常处理等复杂特性,采用“结构体+接口”实现面向对象思想,支持函数多返回值、defer延迟执行、切片(Slice)、映射(Map)等实用特性。代码可读性强,上手快,注重“约定优于配置”。
– Rust语言:语法借鉴了C++和Go,支持泛型、 traits(类似接口)、模式匹配、错误处理(Result/Option类型)等特性,核心是“所有权机制”(每个值有且仅有一个所有者,所有者生命周期结束后自动释放内存)。语法严谨,编译检查严格,上手门槛较高,但一旦掌握,能写出安全且高效的代码。
2.2 关键设计亮点
– C语言:指针操作灵活,能直接访问内存地址,可移植性强(几乎支持所有硬件平台),代码编译后体积小、执行速度快,是底层开发的“基石”。
– C++:支持“零成本抽象”——引入的面向对象、泛型等特性不会带来额外的性能开销,兼顾底层控制与高层抽象,STL标准库提供了丰富的数据结构和算法,大幅提升开发效率。
– Go语言:内置goroutine(轻量级线程,占用内存少、切换成本低)和channel(管道),实现“基于通信的并发模型”,解决了传统多线程的锁竞争问题,能轻松支撑高并发场景;编译速度快,生成单一可执行文件,部署简单(无需依赖运行时)。
– Rust语言:所有权机制+借用规则,在编译期解决内存安全问题,无需垃圾回收,也无需手动管理内存(避免了C/C++的内存泄漏、野指针);支持“零成本抽象”,性能与C/C++相当,同时支持并发安全(编译期检查数据竞争)。
三、类型系统与安全性:从灵活到严谨的演进
| 特性 | C | C++ | Go | Rust |
|---|---|---|---|---|
| 类型安全 | 弱类型 | 强类型(可显式绕过) | 强类型 | 强类型(编译时强制) |
| 类型推断 | 无 | 有限(C++11 auto) | 强(:=声明) | 强(局部变量) |
| 泛型支持 | 无 | 模板(编译时多态) | 1.18+ 泛型 | 泛型 + trait约束 |
| 空安全 | 无(NULL) | 无(nullptr, 仍可能空) | 接口可nil | Option(编译时检查) |
| 默认不可变性 | 否 | 否 | 是 | 是 |
| 代数数据类型 | 无 | 无(可模拟) | 无 | 有(enum模式匹配) |
| 特性 | C | C++ | Go | Rust |
|---|---|---|---|---|
| 主要机制 | 错误码/返回值 | 异常 | 多返回值(err模式) | Result<T,E>枚举 |
| 优点 | 简单、明确 | 非侵入式错误传播 | 显式处理、简单 | 编译时强制处理、无开销 |
| 缺点 | 易忽略、无强制 | 性能开销、控制流模糊 | 冗长、易忽略错误检查 | 代码略显冗长 |
类型系统是编译语言的核心骨架,它决定了语言的表达能力、安全性和编译期的错误检测能力。四种语言在类型系统方面呈现出从弱到强的演进趋势,同时也各具特色。
3.1 C语言:弱类型与信任程序员的哲学
C语言以其“弱类型”特性著称,提供了高度的灵活性但缺乏足够的编译期保护。C语言允许各种隐式类型转换,允许指针的自由转换,允许数组退化为指针等行为。这些特性使得C语言能够高效地操作底层内存,但也为bug的滋生提供了温床。空指针解引用、缓冲区溢出、未初始化变量使用等常见错误在C语言中屡见不鲜。
C语言的类型检查主要依赖编译器的警告机制,而许多警告在默认配置下是不显示的。这意味着C程序员需要具备高度的风险意识,主动启用编译器的高级警告选项(如gcc的-Wall -Wextra),并严格遵守编码规范。静态分析工具(如Clang Static Analyzer、Cppcheck)可以在一定程度上弥补C语言类型系统的不足,但无法从根本上解决问题。
3.2 C++:强类型与复杂的模板元编程
C++在类型系统方面比C更为严格,引入了更丰富的类型修饰符和更完善的类型检查机制。C++还支持模板元编程,使得类型本身可以作为编译期的计算对象。然而,C++也继承了C的许多“灰色地带”,如隐式类型转换规则、拷贝构造函数的自动生成等,这些特性在不经意间可能导致性能问题或微妙的bug。
现代C++(C++11以后)引入了enum class、std::optional、std::variant等更安全的类型构造,显著提升了类型系统的表达能力。模板别名、变参模板、概念(Concepts,C++20)等特性使得泛型编程更加直观和类型安全。但与此同时,C++的复杂性也在不断增长,学习C++意味着需要持续跟进语言特性的演进,这是一项终身的事业。
3.3 Go语言:简洁强类型与接口的鸭子类型
Go语言采用简洁的强类型系统,变量必须有明确的类型声明(尽管可以使用类型推断)。Go的类型系统设计遵循“简单即美”的原则,刻意排除了一些复杂的特性——如传统的类继承体系。Go的接口(Interface)采用鸭子类型(Duck Typing)的语义:只要一个类型实现了接口定义的所有方法,它就自动满足该接口,无需显式声明。
Go 1.18引入了泛型支持,这是Go语言历史上最重要的特性更新之一。在此之前,Go程序员不得不用空接口(interface{})和类型断言来处理通用编程场景,这既不类型安全也不高效。Go的泛型实现采用了类型参数和类型约束的设计,在保持语言简洁性的同时提供了必要的泛型能力。然而,Go的泛型实现被认为过于保守,与C++的模板元编程相比,在表达能力和性能优化空间上仍有差距。
Go语言的另一个独特之处是对错误处理的设计。Go没有异常机制,而是通过返回error类型来处理错误。这种显式的错误处理方式虽然代码冗长,但使得错误流清晰可控,开发者无法忽略错误处理。defer、panic和recover机制则用于处理真正的异常情况。
3.4 Rust:极致类型安全与代数数据类型
Rust拥有四种语言中最强大的类型系统。Rust的类型系统基于代数数据类型(Algebraic Data Types),enum可以包含数据变体,Option和Result类型强制开发者处理可能为空或可能失败的情况。模式匹配(Pattern Matching)配合枚举使用,使得处理复杂状态逻辑既类型安全又表达力丰富。
Rust的借用检查器是其类型系统的核心组成部分,它不仅检查内存安全,还检查数据竞争。生命周期标注(’a、’static等)使得Rust能够精确管理引用有效期,这是Rust能够在没有GC的情况下保证内存安全的根本原因。Rust还提供了不安全代码(unsafe)块,允许在受控范围内绕过某些安全检查,以换取与C/C++相当的底层操作能力。
Rust的特质(Trait)系统提供了类似于接口的功能,但更加强大。特质可以包含默认实现、关联类型、泛型约束等高级特性。Rust 2018 edition引入的impl Trait和dyn Trait进一步丰富了类型系统的表达能力。总体而言,Rust的类型系统在安全性和表达力之间达到了新的平衡点。
四、性能效率:执行速度与编译速度对比
| 指标 | C | C++ | Go | Rust |
|---|---|---|---|---|
| 执行速度 | 100% (基准) | 100-130% | 150-200% | 100-105% |
| 内存占用 | 极低 | 低 | 中等(GC 开销) | 低 |
| 编译速度 | 极快 | 中等(模板膨胀问题) | 极快 | 较慢(借用检查分析) |
| 启动时间 | 极快 | 快 | 快 | 快 |
| 并发性能 | 需手动优化 | 需手动优化 | 优秀(goroutine) | 优秀(零成本抽象) |
编译语言的核心优势之一是高性能,四大语言的性能差异主要体现在执行速度、编译速度两个维度,具体表现与语言设计、内存管理方式密切相关。
4.1 执行速度
执行速度的核心影响因素是“内存管理方式”“是否有运行时开销”“代码优化程度”,四大语言的执行速度排序大致为:C ≈ C++ ≈ Rust > Go。
– C/C++/Rust:三者均无垃圾回收(Rust虽无需手动管理内存,但无GC运行时),能直接操作内存,编译期优化充分,执行速度几乎处于同一水平。其中,C语言因语法极简,无额外抽象开销,在极端场景下略占优势;Rust通过编译器优化,能达到与C/C++完全持平的性能;C++在开启O2/O3优化后,性能与C基本一致。
– Go语言:执行速度略低于前三者,核心原因是内置了垃圾回收(GC),GC运行时会带来轻微的性能开销(尤其是在高并发、大内存场景下)。但Go的GC经过多代优化,延迟已大幅降低,在大多数场景下(如微服务、API服务),性能完全能满足需求,且开发效率远高于C/C++/Rust。
4.2 编译速度
编译速度主要受“语法复杂度”“依赖管理”“编译器优化”影响,排序大致为:Go > C > C++ > Rust。
– Go语言:编译速度极快,这是其核心优势之一。原因是语法简单、无复杂模板、依赖管理简洁(采用模块机制),编译器优化针对性强,即使是大型项目,编译也能在几秒内完成。
– C语言:语法简单,无额外抽象,编译过程简单,编译速度较快,但随着项目规模增大、依赖增多,编译速度会有所下降。
– C++:编译速度较慢,核心原因是支持模板(模板实例化会增加编译开销)、语法复杂、头文件依赖繁琐,大型项目(如Chrome、Qt)编译可能需要几十分钟甚至几小时。
– Rust语言:编译速度最慢,因为编译器需要进行严格的安全检查(所有权、借用、数据竞争等),且泛型、traits等特性会增加编译复杂度,即使是小型项目,编译时间也可能比Go长几倍。
五、内存管理:安全与可控的平衡艺术
| 特性 | C | C++ | Go | Rust |
|---|---|---|---|---|
| 管理方式 | 纯手动(malloc/free) | 手动 + 智能指针 | 自动垃圾回收(GC) | 所有权系统 + 生命周期检查 |
| 内存安全 | 无保障 | 依赖程序员经验 | GC 保障,但存在 STW 停顿 | 编译期强制保证 |
| 悬空指针 | 常见 Bug | 可能(野指针) | GC 避免 | 编译期禁止 |
| 数据竞争 | 无保护 | 无保护 | 运行时检测 | 编译期禁止 |
| 运行时开销 | 零开销 | 零开销(raw ptr) | GC 开销 | 零开销 |
| 确定性释放 | 完全确定 | 确定(RAII) | 不确定 | 确定(Drop trait) |
| 数据竞争预防 | 无编译时保护 | 无编译时保护(依赖规范) | 无编译时保护(race detector) | 编译时防止数据竞争 |
| 主要并发原语 | 手动同步(锁、信号量) | 原子操作、互斥锁、future | goroutine、channel、sync包 | 基于所有权的线程安全保证 |
内存管理是编译语言的核心痛点,也是四大语言差异最大的维度之一——不同的内存管理方式,决定了语言的安全性、开发效率和性能。
– C语言:手动内存管理,通过malloc/free函数手动分配和释放内存。优点是完全可控,无额外开销;缺点是极易出现内存泄漏(忘记free)、野指针(使用已释放的内存)、双重释放等问题,调试难度大,尤其是在大型项目中。
– C++:兼容C的手动内存管理(malloc/free),同时引入了“智能指针”(auto_ptr、shared_ptr、unique_ptr等),可实现半自动内存管理,减少内存安全问题。但智能指针仍存在使用门槛(如循环引用导致内存泄漏),且手动管理的部分依然可能出现安全隐患,整体内存安全性优于C,但远不如Rust。
– Go语言:自动内存管理(垃圾回收,GC),无需手动分配和释放内存,编译器自动跟踪内存使用情况,在合适的时机回收无用内存。优点是开发效率高,无需关注内存细节,减少内存安全问题;缺点是GC会带来轻微的性能开销,且无法完全避免内存泄漏(如循环引用)。
– Rust语言:编译期内存管理(所有权+借用规则),既无需手动管理内存,也无需垃圾回收。通过编译器检查所有权和借用规则,确保内存使用安全,当所有者生命周期结束时,内存自动释放。优点是内存安全(编译期杜绝内存泄漏、野指针),无GC开销,性能优异;缺点是学习门槛高,需要理解所有权、借用、生命周期等概念,编写代码时需遵循严格的规则。
六、并发模型:高并发场景的适配能力
| 维度 | C/C++ | Go | Rust |
|---|---|---|---|
| 并发原语 | 线程 + 锁(pthread/std::thread) | Goroutine + Channel | 线程 + 异步(async/await) |
| 内存模型 | 宽松,需手动同步 | CSP 模型,内存共享通过通信 | 所有权模型自动避免数据竞争 |
| 线程安全 | 无编译期保证 | 运行时保证 | 编译期保证(Send/Sync trait) |
| 开发难度 | 高(易死锁、数据竞争) | 低(语言级支持) | 中(学习曲线陡峭但安全) |
| 适用场景 | 细粒度控制 | 高并发服务 | 高性能并发系统 |
随着分布式系统、云原生的发展,并发能力成为编译语言的核心竞争力。四大语言的并发模型差异显著,适配不同的并发场景。
– C语言:无内置并发支持,需依赖操作系统的多线程(如POSIX线程pthread)或多进程实现并发。并发控制需手动使用互斥锁(mutex)、条件变量等,容易出现锁竞争、死锁等问题,开发难度大,适配高并发场景的成本高。
– C++:在C的基础上,通过STL提供了线程库(std::thread)、互斥锁(std::mutex)、条件变量等,支持多线程并发。但本质上仍是“基于共享内存的并发模型”,需手动管理锁,同样存在锁竞争、死锁等问题,并发开发复杂度高,适合对性能要求极高但并发量不极端的场景(如游戏引擎、高性能计算)。
– Go语言:内置“基于通信的并发模型”,核心是goroutine和channel。goroutine是轻量级线程(每个goroutine占用约2KB内存,可同时创建数十万甚至数百万个),切换成本远低于操作系统线程;channel用于goroutine之间的通信,实现“无锁并发”,避免了锁竞争问题。开发难度低,能轻松支撑高并发场景(如微服务、消息队列、Web服务器),是Go语言最核心的优势之一。
– Rust语言:支持多种并发模型,包括多线程、异步编程(async/await),核心优势是“并发安全”。通过所有权机制和借用规则,编译期检查数据竞争,确保多线程并发时的内存安全,无需手动管理锁(但仍可手动使用锁实现更灵活的并发控制)。同时,Rust的异步编程无运行时开销,性能优于Go的异步,适合对并发安全和性能要求极高的场景(如区块链、高性能服务器)。
七、生态与适用场景:各有所长,精准选型
| 维度 | C | C++ | Go | Rust |
|---|---|---|---|---|
| 包管理器 | 无标准(Makefile/CMake) | 无标准(Conan/vcpkg 尝试统一) | 内置(go modules) | 内置(Cargo) |
| 构建系统 | Make/CMake | CMake/Bazel | go build | Cargo |
| 编译器 | GCC/Clang/MSVC | GCC/Clang/MSVC | GC | rustc(LLVM 后端) |
| 标准库 | 极小(libc) | 庞大(STL + Boost) | 丰富(网络、并发内置) | 丰富(零成本抽象) |
| IDE 支持 | 基础 | 优秀(CLion/VS) | 优秀(VS Code/GoLand) | 优秀(rust-analyzer) |
| 学习曲线 | 中(指针难) | 陡峭(模板、元编程) | 平缓 | 陡峭(所有权系统) |
语言的生态成熟度和适用场景,决定了它在实际开发中的落地能力。四大语言的生态各有侧重,适配不同的行业和项目类型。
7.1 生态成熟度
– C语言:生态极其成熟,诞生几十年,拥有大量的开源库和工具(如OpenSSL、MySQL底层),几乎支持所有硬件平台,是底层开发的“标配”。但生态相对老旧,缺乏现代开发所需的便捷工具(如包管理工具)。
– C++:生态同样成熟,STL标准库功能强大,拥有大量开源框架(如Qt、Boost、Chrome内核),覆盖游戏、桌面应用、高性能计算等多个领域。但生态复杂度高,不同版本的编译器、库之间兼容性较差。
– Go语言:生态发展迅速,由Google主导,拥有丰富的官方库和第三方库(如Gin、Echo、Kubernetes),主打云原生、微服务、Web开发,工具链完善(如go mod包管理、go test测试工具),社区活跃。
– Rust语言:生态处于快速发展阶段,拥有 Cargo 包管理工具、Rustup 版本管理工具,第三方库数量不断增加(如Tokio异步框架、Actix Web服务器),社区活跃,但整体生态规模仍不及C/C++/Go,部分领域(如桌面应用)的库相对薄弱。
7.2 适用场景
– C语言:适合底层开发,如操作系统内核(Linux、Windows内核部分)、嵌入式系统(单片机、物联网设备)、驱动程序、数据库底层(MySQL、PostgreSQL内核)等,追求极致性能和内存可控的场景。
– C++:适合对性能和灵活性要求高的场景,如游戏引擎(Unreal Engine、Unity底层)、桌面应用(Qt开发)、高性能计算(科学计算、人工智能训练框架底层)、浏览器内核等,可兼顾底层控制与高层抽象。
– Go语言:适合云原生、高并发场景,如微服务(Kubernetes、Docker)、Web服务器(Gin、Echo)、消息队列(RabbitMQ客户端)、分布式系统等,追求开发效率和并发能力的平衡。
– Rust语言:适合对安全和性能要求极高的场景,如操作系统(Redox OS)、嵌入式系统(安全物联网设备)、区块链(Solana、Polkadot)、高性能服务器、加密货币等,解决C/C++的内存安全问题。
八、总结:如何选择适合自己的编译语言?
| 评估维度 | 推荐排序(降序) |
|---|---|
| 极致性能 | C ≈ Rust ≈ C++ > Go |
| 开发效率 | Go > Rust > C++ > C |
| 内存安全 | Rust > Go > C++ > C |
| 系统控制 | C > C++ ≈ Rust > Go |
| 并发安全 | Rust > Go > C++ > C |
| 生态成熟度 | C++ > Go > C > Rust |
| 长期可维护性 | Rust > Go > C++ > C |
四大主流编译语言没有绝对的“优劣之分”,只有“适配与否”,结合自身需求和场景,才能做出最优选择:
1. 如果做底层开发、嵌入式、操作系统,追求极致性能和内存可控,选 C语言;若需要兼顾面向对象和代码复用,选 C++。
2. 如果做云原生、微服务、Web开发、高并发服务,追求开发效率和并发能力,选 Go语言,上手快、部署简单,能快速落地项目。
3. 如果做安全敏感、高性能的场景(如区块链、嵌入式安全、高性能服务器),需要杜绝内存安全问题,选 Rust语言,虽然学习门槛高,但能大幅降低后期维护成本。
从发展趋势来看,Go语言凭借其简单高效的特性,在云原生领域的地位持续提升;Rust语言则凭借内存安全和高性能,逐渐替代C/C++在部分安全敏感场景的应用;而C/C++作为经典语言,仍将在底层开发、高性能计算等领域长期占据主导地位。
无论选择哪门语言,核心都是“用合适的工具解决合适的问题”,掌握其核心设计哲学和技术特性,才能真正发挥语言的优势。