代码跨平台怎么实现?6大核心方案+场景选型,告别重复开发
做开发时最头疼的莫过于 “一套代码多端适配”——Windows、Mac、Linux 要适配,iOS、Android 要兼容,甚至还要兼顾浏览器和小程序。重复写多套代码不仅效率低,还容易出现兼容性 bug。其实跨平台开发早已不是新鲜事,不同技术方案各有优劣,关键是选对适配场景。今天就拆解代码跨平台的核心实现方式,帮你快速找准适合自己的方案。
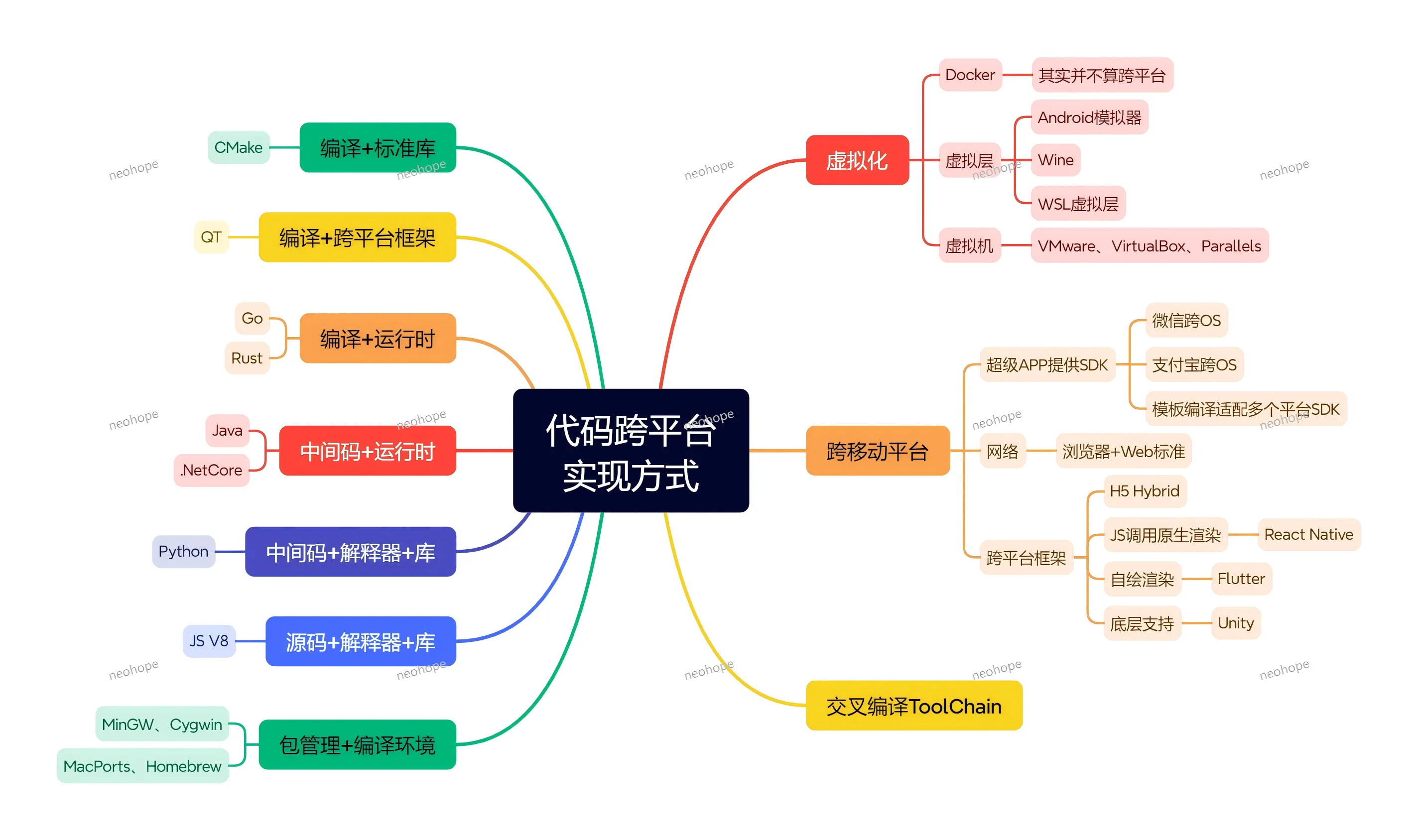
一、编译适配型:一次编码,多平台编译
核心逻辑:编写统一源码,通过专用编译工具或语言特性,直接编译出不同平台的可执行文件,性能接近原生。
代表技术:
语言原生支持:Go(编译 + 运行时,直接编译为各平台二进制文件)、Rust(跨平台编译工具链,适配多系统)、Java(中间码 + JVM 运行时,一次编译多平台运行)、.NET Core(中间码 + 运行时,跨 Windows/Mac/Linux);
编译工具辅助:CMake(搭配标准库,统一管理多平台编译流程)、交叉编译 ToolChain(如 MinGW、Cygwin,实现跨系统编译);
优势:性能强,接近原生应用;代码复用率高,无需大幅修改;
适用场景:后端服务、工具类软件、高性能应用(如 Go 开发的跨平台服务器,C+++CMake 开发的桌面工具)。
二、跨平台框架型:框架封装,屏蔽平台差异
核心逻辑:基于统一框架开发,框架底层适配不同平台的 API,开发者无需关注平台细节,专注业务逻辑。
代表技术:
桌面 / 多端框架:QT(编译 + 跨平台框架,适配桌面 + 嵌入式,支持 C++/QML);
移动跨平台框架:React Native(JS 调用原生渲染,兼顾跨平台与原生体验)、Flutter(自绘渲染引擎,跨 iOS/Android/ 桌面 / 网页,UI 一致性强);
优势:开发效率高,一套代码覆盖多端;UI 适配性好,框架已处理平台差异;
适用场景:移动 APP(如电商 APP、工具类 APP)、桌面应用(如 QT 开发的跨平台客户端)、中小型项目(Flutter 快速迭代上线)。
三、虚拟层/模拟型:通过虚拟环境兼容多平台
核心逻辑:在目标平台上搭建虚拟层或模拟器,让原本不兼容的代码在虚拟环境中运行,无需修改源码。
代表技术:
虚拟机:VMware、VirtualBox、Parallels(在 Windows/Mac上虚拟出其他操作系统,运行对应平台软件);
兼容层:Wine(在Linux/Mac上模拟 Windows 运行环境,运行 Windows 程序)、WSL(Windows子系统,在Windows上运行 Linux 环境及软件);
模拟器:Android 模拟器(在PC上模拟Android环境,运行APP);
优势:无需修改原有代码,直接复用现有应用;门槛低,快速实现兼容;
注意点:性能有损耗,不如原生流畅;部分复杂应用可能出现兼容性问题;
适用场景:现有应用跨平台运行(如Windows软件在Linux上通过Wine运行)、开发测试(Android模拟器调试APP)。
四、超级APP生态型:依托生态,跨OS运行
核心逻辑:在微信、支付宝等超级APP提供的SDK或生态内开发,借助超级APP的跨平台能力,实现 “一次开发,多OS适配”。
代表技术:微信跨OS、支付宝跨OS(通过其提供的 SDK 开发小程序或内嵌应用,自动适配 iOS/Android);
优势:无需考虑底层平台适配,超级 APP 已完成兼容;流量红利,可直接触达超级 APP 的海量用户;
适用场景:小程序、内嵌应用(如微信小程序、支付宝生活号应用)、轻量级交互场景。
五、Web标准型:基于浏览器,跨平台无压力
核心逻辑:采用 HTML/CSS/JS 开发,依托浏览器的 Web 标准,实现 “一次开发,所有浏览器兼容”,间接跨所有支持浏览器的平台。
代表技术:浏览器 + Web 标准、H5 Hybrid(APP 内嵌 WebView,混合原生与 Web 页面);
优势:兼容性极强,覆盖 PC / 移动 / 平板所有浏览器;开发成本低,技术栈普及;
注意点:性能依赖浏览器,复杂交互体验不如原生;部分原生 API 需通过桥接调用;
适用场景:网页应用、轻量级 APP、跨平台展示型场景(如官网、数据可视化页面、Hybrid APP 的展示模块)。
六、包管理与环境配置型:统一环境,简化适配
核心逻辑:通过包管理工具统一管理依赖,确保不同平台的开发环境一致,减少因环境差异导致的适配问题。
代表技术:MacPorts、Homebrew(Mac 平台包管理工具,快速安装适配 Mac 的开发依赖);
优势:简化环境配置,快速搭建跨平台开发所需依赖;统一依赖版本,避免 “本地能跑,线上报错”;
适用场景:辅助跨平台开发(如通过 Homebrew 在 Mac 上安装 CMake、MinGW 等跨平台编译依赖)。
总结:跨平台方案选型核心逻辑 ——“场景决定方案”
不用盲目追求 “万能方案”,选型时重点关注3点:
1、性能需求:高性能场景(后端、工具软件)选编译适配型(Go/Rust/CMake);中低性能需求(展示型 APP、小程序)选 Web 标准或超级 APP 生态;
2、多端覆盖范围:需覆盖移动 + 桌面选 Flutter/QT;仅移动端选 React Native/Flutter;仅桌面端选 QT/Go 编译;
3、开发效率:快速迭代选 Flutter/React Native;追求长期稳定、低维护成本选编译适配型或 QT。
跨平台开发的核心是 “用最低成本实现多端兼容”,不同方案没有绝对优劣,只有是否适配场景。选对方案,既能减少重复开发,又能保证产品体验。
你在跨平台开发中遇到过哪些兼容性坑?或者你更倾向于哪种实现方案?欢迎在评论区留言交流~