1、关闭cluster全部节点
2、删除所有nodes.conf文件
3、开启全部节点
4、依次flushall
5、重建集群即可
Category Archives: Database
Redis3配置Cluster
1、redis3的cluster是基于ruby的,所以要安装好ruby,然后安装redis的gem
gem install redis
2、然后配置6份redis,修改配置如下
| 节点 | ||||||
| dbm6379 | dbm6380 | dbm6381 | dbs6382 | dbm6383 | dbm6384 | |
| 配置文件 | dbm6379/conf/redis.conf | dbm6380/conf/redis.conf | dbm6381/conf/redis.conf | dbs6382/conf/redis.conf | dbm6383/conf/redis.conf | dbm6384/conf/redis.conf |
| port | 6379 | 6380 | 6381 | 6382 | 6383 | 6384 |
| logfile | “/home/neohope/DB/redis-3.0.4/cluster/dbm6379/logs/redis_log.log” | “/home/neohope/DB/redis-3.0.4/cluster/dbm6380/logs/redis_log.log” | “/home/neohope/DB/redis-3.0.4/cluster/dbm6381/logs/redis_log.log” | “/home/neohope/DB/redis-3.0.4/cluster/dbm6382/logs/redis_log.log” | “/home/neohope/DB/redis-3.0.4/cluster/dbm6383/logs/redis_log.log” | “/home/neohope/DB/redis-3.0.4/cluster/dbm6384/logs/redis_log.log” |
| dir | “/home/neohope/DB/redis-3.0.4/cluster/dbm6379/data” | “/home/neohope/DB/redis-3.0.4/cluster/dbm6380/data” | “/home/neohope/DB/redis-3.0.4/cluster/dbm6381/data” | “/home/neohope/DB/redis-3.0.4/cluster/dbm6382/data” | “/home/neohope/DB/redis-3.0.4/cluster/dbm6383/data” | “/home/neohope/DB/redis-3.0.4/cluster/dbm6384/data” |
| cluster-enabled | yes | yes | yes | yes | yes | yes |
| cluster-config-file | nodes-6379.conf | nodes-6380.conf | nodes-6381.conf | nodes-6382.conf | nodes-6383.conf | nodes-6384.conf |
| cluster-node-timeout | 15000 | 15000 | 15000 | 15000 | 15000 | 15000 |
| cluster-migration-barrier | 1 | 1 | 1 | 1 | 1 | 1 |
| cluster-require-full-coverage | yes | yes | yes | yes | yes | yes |
3、启动redis
#!/bin/sh ~/DB/redis-3.0.4/bin/redis-server ~/DB/redis-3.0.4/cluster/dbm6379/conf/redis.conf & echo $! & ~/DB/redis-3.0.4/bin/redis-server ~/DB/redis-3.0.4/cluster/dbm6380/conf/redis.conf & echo $! & ~/DB/redis-3.0.4/bin/redis-server ~/DB/redis-3.0.4/cluster/dbm6381/conf/redis.conf & echo $! & ~/DB/redis-3.0.4/bin/redis-server ~/DB/redis-3.0.4/cluster/dbs6382/conf/redis.conf & echo $! & ~/DB/redis-3.0.4/bin/redis-server ~/DB/redis-3.0.4/cluster/dbs6383/conf/redis.conf & echo $! & ~/DB/redis-3.0.4/bin/redis-server ~/DB/redis-3.0.4/cluster/dbs6384/conf/redis.conf & echo $!
4、配置cluster
#!/bin/sh #这里最好不要用127.0.0.1做地址 ~/DB/redis-3.0.4/bin/redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
5、测试redis cluster
~/DB/redis-3.0.4/bin/redis-cli -c -p 6379 set key01 a set key02 b set key03 c set key04 d dbsize keys * get key03
6、关闭redis
#!/bin/sh ~/DB/redis-3.0.4/bin/redis-cli -p 6379 shutdown ~/DB/redis-3.0.4/bin/redis-cli -p 6380 shutdown ~/DB/redis-3.0.4/bin/redis-cli -p 6381 shutdown ~/DB/redis-3.0.4/bin/redis-cli -p 6382 shutdown ~/DB/redis-3.0.4/bin/redis-cli -p 6383 shutdown ~/DB/redis-3.0.4/bin/redis-cli -p 6384 shutdown
Redis主从数据库(Shell)
1、基本配置如下
| 数据库 | master | slave01 | slave02 |
| 配置文件 | redis.master.conf | redis.slave01.conf | redis.slave02.conf |
| ip地址 | localhost | localhost | localhost |
| 端口 | 6379 | 6380 | 6381 |
| logfile | “D:/Database/Redis2.8/mirror/master/logs/redis_log.txt” | “D:/Database/Redis2.8/mirror/slave01/logs/redis_log.txt” | “D:/Database/Redis2.8/mirror/slave02/logs/redis_log.txt” |
| dir | “D:/Database/Redis2.8/mirror/master/data/” | “D:/Database/Redis2.8/mirror/slave01/data/” | “D:/Database/Redis2.8/mirror/slave02/data/” |
| slaveof | – | localhost 6379 | localhost 6379 |
| slave-serve-stale-data | – | yes | yes |
| slave-read-only | – | yes | yes |
| slave-priority | – | 100 | 100 |
| maxheap | – | 1073741824 | 1073741824 |
| heapdir | – | D:\Database\Redis2.8\mirror\slave01\heap | D:\Database\Redis2.8\mirror\slave02\heap |
2、启动
redis-server.exe D:\Database\Redis2.8\mirror\redis.master.conf redis-server.exe D:\Database\Redis2.8\mirror\redis.slave01.conf redis-server.exe D:\Database\Redis2.8\mirror\redis.slave02.conf
3、测试
D:\Database\Redis2.8>redis-cli 127.0.0.1:6379> dbsize (integer) 0 127.0.0.1:6379> set key01 a OK 127.0.0.1:6379> exit D:\Database\Redis2.8>redis-cli -p 6380 127.0.0.1:6380> get key01 "a" 127.0.0.1:6380> set key02 b (error) READONLY You can't write against a read only slave. 127.0.0.1:6380> exit D:\Database\Redis2.8>redis-cli -p 6381 127.0.0.1:6381> get key01 "a" 127.0.0.1:6381> set key02 b (error) READONLY You can't write against a read only slave. 127.0.0.1:6381> exit
4、关闭
redis-cli -p 6380 shutdown redis-cli -p 6381 shutdown redis-cli -p 6379 shutdown
NOSQL数据库分类
NOSQL:Not Only SQL
1、列存储(Wide Column Store / Column Families),如
Hadoop / HBase
Cassandra
Hypertable
2、文档存储(JSSON),如
MongoDB
CouchDB
3、文档存储(XML)
EMC Documentum xDB
Berkeley DB XML
4、图形存储(Graph)
Neo4J
TITAN
5、对象存储(Object Databases)
Versant
ObjectDB
6、键值存储(Key Value / Tuple Store)
DynamoDB
Redis
Berkeley DB
7、多值数据库
U2
TigerLogic PICK
8、多模型(Multimodel Databases)
ArangoDB
OrientDB
9、多维(Multidimensional Databases)
Intersystems Cache
MiniM DB
10、网格/云(Grid & Cloud Database Solutions)
Oracle Coherence
Hazelcast
11、事件源(Event Sourcing)
Event Store
12、网络模型(Network Model)
Vyhodb
MongoDB数据引用(Shell)
1、被引用数据
db.address.insert({"city":"shanghai","street":"huaihai road","no":"101"})
db.address.insert({"city":"beijing","street":"taipingqiao road","no":"102"})
2、引用数据
db.persons.insert({"name":"joe","address":{"$ref":"address","$id": ObjectId("55f522e96811e30fd403e83d"),"$db": "test"},"age":20,"sex":"male"})
db.persons.insert({"name":"leo","address":{"$ref":"address","$id": ObjectId("55f522f46811e30fd403e83e"),"$db": "test"},"age":21,"sex":"male"})
3、查询被引用数据
var user = db.persons.findOne({"name":"joe"})
var addressRef = user.address
db[addressRef.$ref].findOne({"_id":(addressRef.$id)})
MongoDB备份还原(Shell)
1、备份
mongodump --host localhost --port 27027 -d test -c patient -o D:\Database\MongoDB3\backup
2、还原
mongorestore --host localhost --port 27027 --drop -d test D:\Database\MongoDB3\backup
MongoDB的ObjectId(Shell)
MongoDB中存储的文档必须有一个”_id”键。这个键的值可以是任何类型的,默认是个ObjectId对象。该_id用来确保集合里面每个文档都能被唯一标识,并用来在多个服务器上同步数据。
ObjectId是一个12字节BSON类型数据,格式如下:
前4个字节表示时间戳
接下来的3个字节是机器标识码
接的两个字节由进程id组成(PID)
最后三个字节是随机数
myObjectId = ObjectId() myObjectId.getTimestamp()
ACID、BASE与CAP
一、关系型数据库遵循的ACID原则
1、A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
2、C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
3、I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
比如现有有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
二、非关系型数据库遵循的BASE原则
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
1、Basically Availble –基本可用
2、Soft-state –软状态/柔性事务。 “Soft state” 可以理解为”无连接”的, 而 “Hard state” 是”面向连接”的
3、Eventual Consistency –最终一致性 最终一致性, 也是是 ACID 的最终目的。
三、CAP定理(CAP theorem)
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer’s theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
1、一致性(Consistency) (所有节点在同一时间具有相同的数据)
2、可用性(Availability) (保证每个请求不管成功或者失败都有响应)
3、分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
CA – 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
CP – 满足一致性,分区容忍必的系统,通常性能不是特别高。
AP – 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
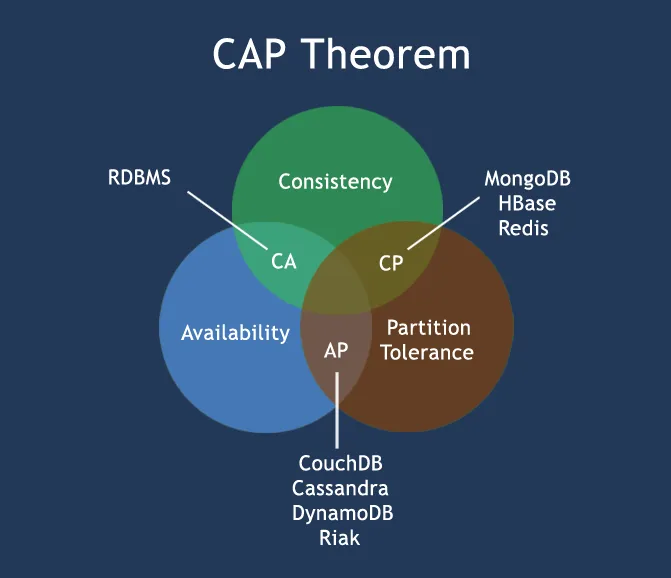
举个例子来说,HBase与Cassandra,HBase在CAP中,更偏重于CP,客户端读到的数据是一致的,但性能会差;而Cassandra更偏重于AP,性能好一些,但有时客户端会读到不同的数据。
MongoDB聚合操作(Shell)
0、数据准备
for(var i=0;i<10000;i++){
var patid="pat"+i;
var patname="name"+i;
var sex="M";
var age=parseInt(100*Math.random(i));
db.patient.insert({"patid":patid,"patname":patname,"sex":sex,"age":age,address:{"city":"shanghai","street":"huaihai road"}});
}
1、count
db.patient.count({"age":12})
2、distinct
db.patient.distinct("age")
3、min, max, sum,avg
db.patient.aggregate([{$group:{_id:"$item",maxAge:{$max:"$age"}}}])
db.patient.aggregate([{$group:{_id:"$item",minAge:{$min:"$age"}}}])
db.patient.aggregate([{$group:{_id:"$item",sumAge:{$sum:"$age"}}}])
db.patient.aggregate([{$group:{_id:"$item",avgAge:{$avg:"$age"}}}])
4、group
db.patient.group({
"key":{"age":true},
"initial":{"patids":[]},
"reduce":function(item,out){out.patids.push(item.patid);},
"finalize":function(out){out.count=out.patids.length;},
"condition":{"age":{$lte:18}}
})
5、map reduce
map=function(){emit(this.age,1);}
reduce=function(key,values){return values.length;}
mropt={"out":"mrresult"}
db.patient.mapReduce(map,reduce,mropt).find()
MongoDB更新操作(Shell)
0、数据准备
for(var i=0;i<10000;i++){
var patid="pat"+i;
var patname="name"+i;
var sex="M";
var age=parseInt(100*Math.random(i));
db.patient.insert({"patid":patid,"patname":patname,"sex":sex,"age":age,address:{"city":"shanghai","street":"huaihai road"}});
}
1、默认为全局更新
db.patient.find({"patid":"pat100"})
db.patient.update({"patid":"pat100"},{"patid":"pat100","sex":"F"})
db.patient.find({"patid":"pat100"})
2、局部更新$set
db.patient.find({"patid":"pat101"})
db.patient.update({"patid":"pat101"},{$set:{"sex":"F"}})
db.patient.find({"patid":"pat101"})
3、局部更新$inc
db.patient.find({"patid":"pat102"})
db.patient.update({"patid":"pat102"},{$inc:{"age":-100}})
db.patient.find({"patid":"pat102"})
4、批量更新
db.patient.find({"age":10})
db.patient.update({"age":10},{$set:{"age":11}})
db.patient.find({"age":10})
db.patient.update({"age":10},{$set:{"age":11}},false,true)
db.patient.find({"age":10})
5、更新时,没有匹配则插入
db.patient.find({"patid":"pidx001"})
db.patient.update({"patid":"pidx001"},{"patid":"pidx001","sex":"F"},true)
db.patient.find({"patid":"pidx001"})