在如今的分布式系统、高并发场景中,Redis绝对是绕不开的存在——它既是高性能的缓存中间件,也是灵活的键值数据库,甚至能承担消息队列、分布式锁等多种角色。很多开发者日常都会用Redis,但大多停留在“set/get”的基础用法,对它为什么快、支持哪些核心场景、背后靠什么架构和算法实现这些特性,却了解不深。今天就来一篇干货,从核心定位切入,逐步拆解Redis的功能、特性、架构、算法,结合版本演进和典型应用,帮大家真正读懂Redis的核心技术体系。
一、核心定位与功能概览
要真正理解Redis,首先要明确它的核心定位——它并非单纯的缓存工具,而是一款融合了内存数据库、数据结构服务器、高性能键值存储的多面手,同时支持持久化、高可用和分布式扩展,适配从单机到集群、从简单缓存到复杂业务的全场景需求。
1. 基础定位
A. 内存数据库(In-Memory Data Store):所有核心数据存储在内存中,这是其高性能的核心基础,同时通过持久化机制避免数据丢失;
B. 数据结构服务器(Data Structure Server):区别于传统键值存储,原生支持多种复杂数据结构,可直接支撑复杂业务逻辑,无需额外数据转换;
C. 支持持久化、高可用、分布式的高性能键值存储:兼顾性能与数据安全,支持主从复制、哨兵、集群等部署模式,可灵活扩展,适配高并发、海量数据场景。
2. 核心功能
Redis的功能覆盖多个业务域,形成完整的功能矩阵,可根据场景灵活选用,具体如下:
A. 缓存功能:主要用于热点数据加速、会话存储和页面缓存,能够有效缓解后端数据库压力;
B. 消息队列功能:支持Pub/Sub(发布/订阅)和Streams(流处理)两种模式,分别适配轻量级通知和复杂消息队列场景;
C. 实时计算功能:可实现计数器、排行榜、限流器、地理位置计算等需求,支撑实时数据处理;
D. 会话管理功能:能够实现分布式Session和Token黑名单管理,解决分布式系统会话一致性问题;
E. 全栈数据结构支持:支持String、Hash、List、Set、Sorted Set、Bitmap、HyperLogLog、Geo、Stream等多种类型,可适配各类不同的业务场景。
二、Redis核心功能:基于功能矩阵的详细拆解
结合核心功能矩阵,将Redis的核心功能进一步拆解,明确各功能的实现方式、底层支撑和典型应用,让每个功能的价值和用法更清晰:
1. 数据结构服务器(核心基础功能)
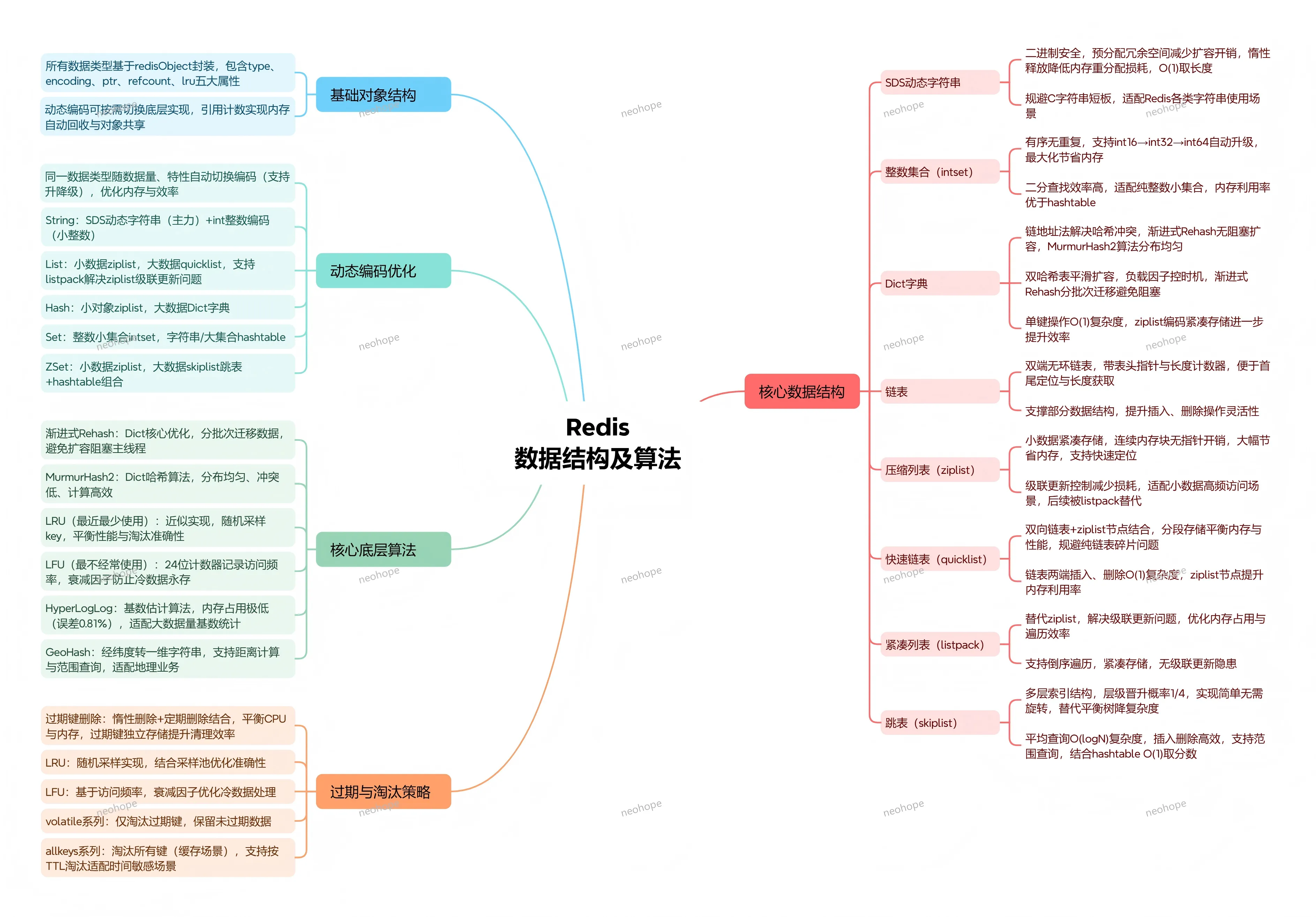
作为核心的数据结构服务器,Redis支持多种丰富的数据类型,远超传统键值存储,可直接支撑复杂业务逻辑,无需额外进行数据转换,提升开发效率,每种数据类型均对应特定的底层实现和业务场景,具体如下:
A. String(字符串):底层实现为SDS(Simple Dynamic String),采用预分配+惰性释放的核心机制,能实现O(1)获取长度且支持二进制安全,典型应用场景包括用户Token、验证码、商品库存、实时计数等;
B. Hash(哈希):小数据量时采用ziplist实现,大数据量时切换为hashtable,通过渐进式rehash和负载因子控制避免阻塞,适合存储用户信息、商品详情等对象类数据;
C. List(列表):3.2版本及以上采用quicklist实现,该结构由ziplist和双向链表组合而成,通过压缩节点减少内存占用,支持两端O(1)插入和删除操作,可用于消息队列、最新消息展示(如朋友圈点赞)等场景;
D. Set(集合):整数小集合时采用intset编码,大数据量时使用hashtable,通过整数编码优化提升性能,支持交集、并集、差集运算,适用于好友去重、共同好友、标签匹配等需求;
E. Sorted Set(有序集合):小数据量时用ziplist,大数据量时采用跳表(skiplist)结合hashtable的方式,跳表实现O(logN)的范围查询,哈希表实现O(1)的分值查询,是实时排行榜、热度排序(如视频播放量)的核心支撑;
F. Bitmap(位图):底层基于String(SDS)实现,通过位运算完成SETBIT/GETBIT操作,且操作效率为O(1),占用内存极少,适合用户签到、在线状态、布尔型统计等场景;
G. HyperLogLog:采用稀疏/密集编码的概率算法,基数统计误差仅为0.81%,且固定占用12KB内存,主要用于独立访客(UV)、独立IP统计等海量数据基数统计场景;
H. Geo(地理位置):底层依赖Sorted Set,通过GeoHash编码将二维坐标转换为一维分数,支持距离计算,可实现外卖、打车、社交等场景的附近地点查询;
I. Stream(流):底层实现为Radix Tree(基数树),支持消息ID自增、消费者组管理和ACK机制,且支持持久化,适用于复杂消息队列、流处理场景。
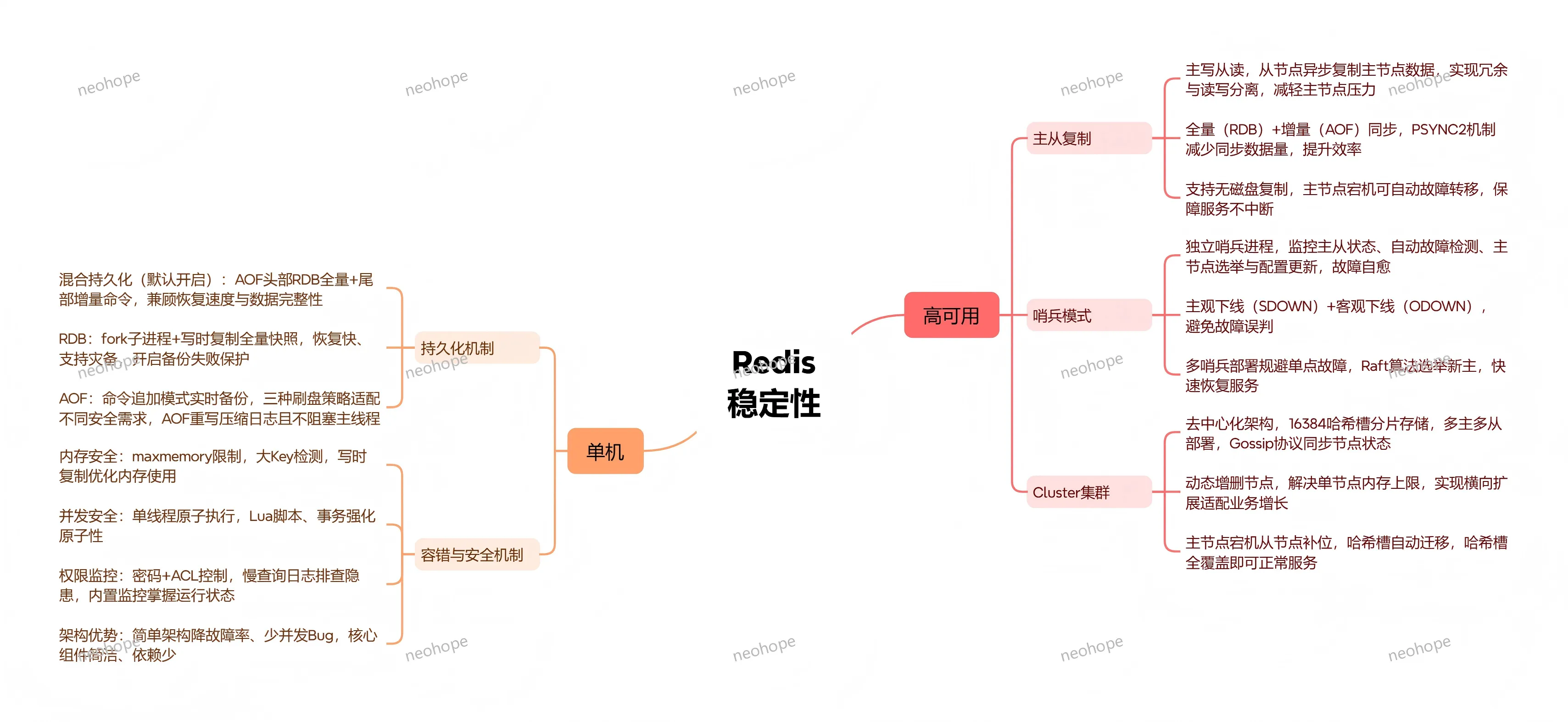
2. 持久化功能
持久化是Redis避免内存数据丢失的核心功能,提供三种持久化方式,可根据业务对数据安全性和性能的需求灵活选择,具体如下:
A. RDB(快照):基于fork() + COW(写时复制)实现,属于全量快照模式,生成的二进制文件紧凑,数据恢复速度快,但缺点是快照之间的新增数据可能丢失;
B. AOF(追加日志):采用命令追加+重写机制(Rewrite),以日志形式存储所有写命令,数据安全性高,支持always、everysec、no三种fsync策略,但存在文件体积大、恢复速度慢的问题;
C. 混合模式(4.0版本及以上支持):结合了RDB和AOF的优势,采用RDB头+AOF尾的结构,重启时先加载RDB快速恢复大部分数据,再重放AOF增量命令,既能保证恢复速度,又能提升数据安全性,是生产环境的首选方案。
关键算法:COW(Copy-On-Write,写时复制)
当Redis需要生成RDB快照或进行主从全量同步时,会通过fork()创建子进程,子进程与主进程共享内存页;当主进程修改数据时,会复制该内存页并修改,子进程继续读取原内存页生成快照,确保快照期间主进程服务不阻塞,兼顾性能与数据一致性。
3. 复制功能
复制功能是Redis实现高可用和读写分离的基础,通过将主节点数据同步到从节点,实现数据冗余,同时分担主节点读压力,核心支持三种机制,具体如下:
A. 全量同步:主节点生成RDB文件传输给从节点,从节点加载RDB后,主节点再发送缓冲区积压的增量命令,完成同步;
B. 部分重同步(PSYNC 2.0):基于复制偏移量和Replication Backlog(复制积压缓冲区),网络闪断后无需全量同步,仅同步中断期间的增量命令,提升同步效率;
C. 无磁盘复制(diskless):主节点生成RDB后,不写入磁盘,直接通过socket传输给从节点,避免磁盘I/O开销,适用于磁盘性能较差的场景。
此外,Redis还支持链式复制(“主-从-从”结构),从节点可作为其他从节点的主节点,减少主节点的复制压力,适用于大规模集群场景。
4. 高可用与集群功能
Redis通过哨兵模式和集群模式,实现高可用和分布式扩展,避免单点故障,支撑海量数据和高并发场景,核心分为三大模块,具体如下:
A. 主从复制(Replication):基础高可用方案,采用“一主多从”架构,主节点负责写操作,从节点负责读操作,实现读写分离,同时通过复制机制保证数据冗余;当主节点故障时,可手动将从节点切换为主节点,保障服务持续可用。
B. 哨兵模式(Sentinel):由多个哨兵节点组成的监控集群,自动实现主从故障检测和转移,无需人工干预,其核心功能及实现机制如下:
故障发现:通过主观下线(SDOWN)和客观下线(ODOWN)判断主节点状态,基于Gossip协议同步节点状态;
领导者选举:基于Raft算法变种,哨兵节点间投票选举出leader哨兵,由leader负责发起故障转移;
配置传播:通过Pub/Sub机制通知所有客户端主从切换信息,确保客户端连接新主节点。
C. 集群模式(Cluster):Redis官方提供的分布式集群方案,采用去中心化设计,支持数据自动分片和故障转移,适配海量数据和高并发场景,其核心特性及支撑架构如下:
数据分片:通过CRC16(key) % 16384算法分配槽位,共16384个slot,每个节点负责一部分槽位存储;
节点通信:基于Gossip协议,节点间通过PING/PONG消息交换状态,实现故障检测和状态同步;
请求路由:通过MOVED/ASK命令重定向请求,Smart Client会缓存槽位映射,减少重定向开销;
故障转移:从节点发起选举,集群多数派(majority)投票确认(基于Raft思想),选举新主节点接管槽位;
在线扩容:通过reshard命令实现槽位迁移,渐进式数据搬迁,不影响集群正常服务。
5. 其他核心功能
除上述核心功能外,Redis还提供一系列实用功能,进一步提升灵活性和扩展性,支撑复杂业务场景,具体如下:
A. 发布/订阅(Pub/Sub):基于频道(Channel)与模式(Pattern)的事件分发机制,支持一对多、多对多的消息推送,适用于轻量级通知场景(如系统公告、实时消息推送),底层基于简单的事件订阅机制实现。
B. 管道(Pipeline):支持批量发送多个命令,减少客户端与Redis服务器的网络交互次数,提升批量操作效率(如批量插入、批量查询),核心是将多个命令打包一次性发送,服务器批量响应,减少网络延迟。
C. Lua脚本:内嵌Lua解释器,支持Lua脚本的原子执行,可将复杂的业务逻辑(如多步命令组合)封装为脚本,在Redis服务端执行,减少网络开销,同时保证逻辑原子性,避免并发修改导致的数据不一致,支持EVAL/EVALSHA命令。
D. 事务:支持MULTI、EXEC、DISCARD等命令,将一组命令打包形成命令队列,实现原子性执行(要么全部执行,要么全部不执行),但不支持回滚,仅保证命令顺序执行;同时支持WATCH命令实现乐观锁,基于CAS(Compare And Swap)语义监控键的变化。
E. 键过期(TTL):支持给任意键设置过期时间,通过多种过期删除策略,自动删除过期键,释放内存,适用于缓存场景(如热点数据自动过期),底层结合惰性删除和定期删除策略实现。
F. 布隆过滤器(通过模块):Redis本身不自带布隆过滤器,需通过RedisBloom等扩展模块实现,基于布隆过滤算法,通过多个哈希函数将元素映射到二进制位,快速判断元素是否存在,误判率可配置,适用于去重、缓存穿透防护等场景。
G. 限流器:可通过Sorted Set实现滑动窗口限流器,或通过Redis Cell模块实现令牌桶限流器,控制接口请求频率,避免高并发压垮后端服务。
三、Redis核心特性与支撑架构/算法
Redis之所以能在众多缓存中间件中脱颖而出,核心在于它的五大核心特点,这些特点相互支撑,让Redis能适配高并发、低延迟、高可用的各类场景,每一个特点背后都有对应的架构和算法深度支撑:
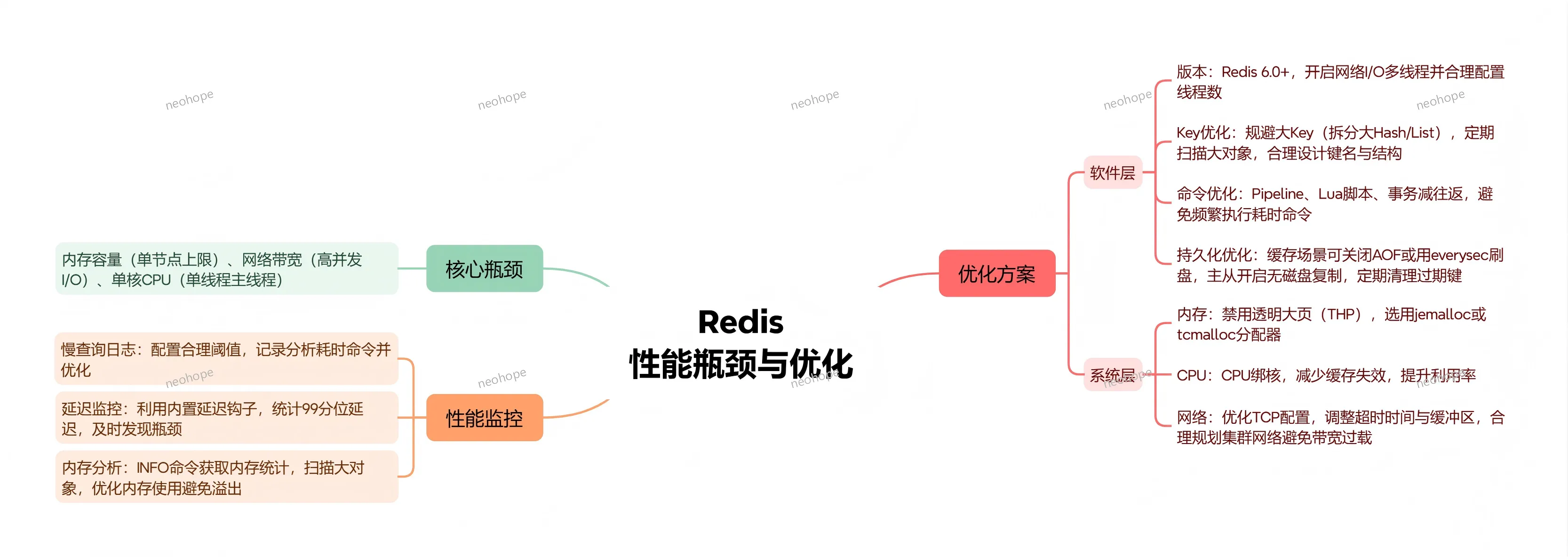
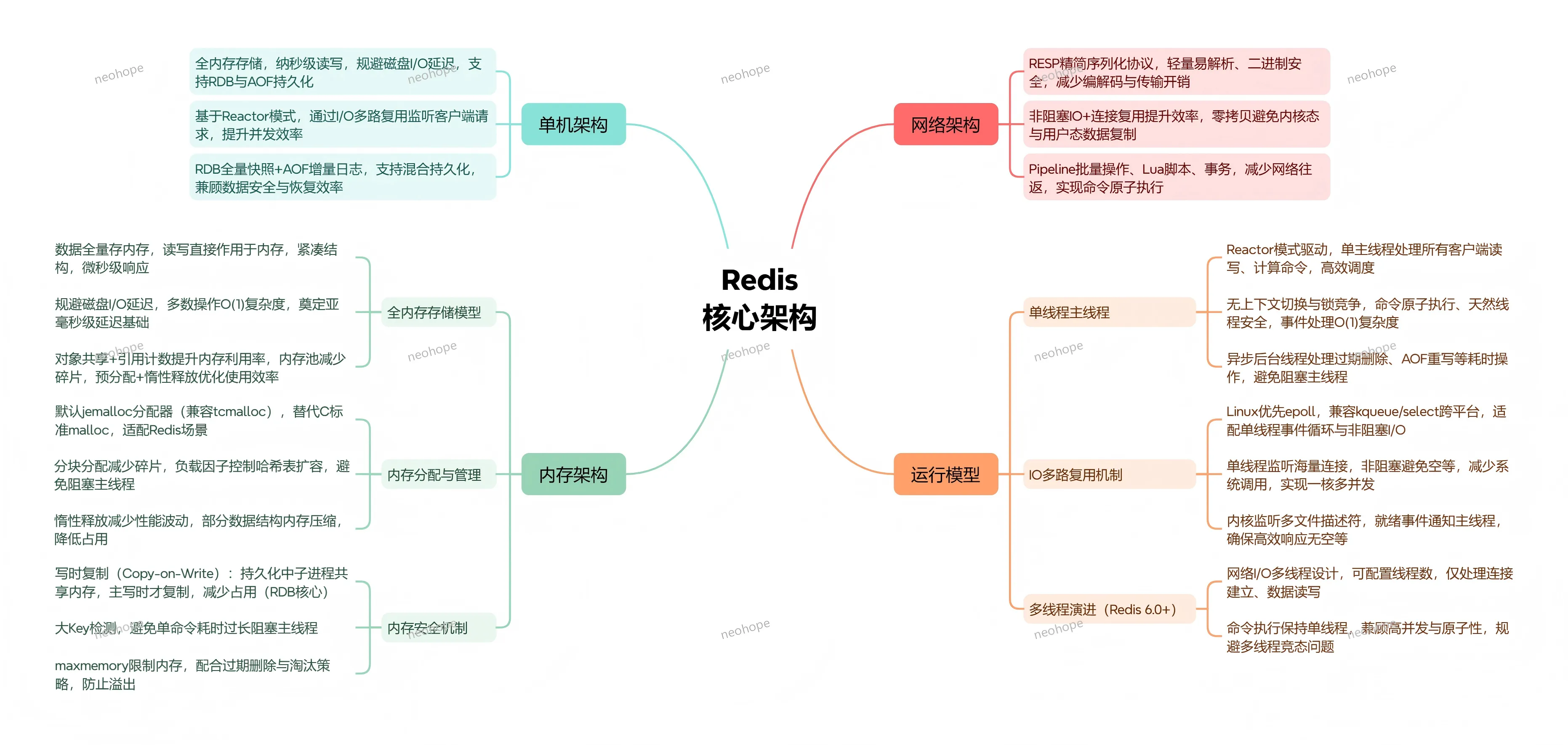
1. 高性能(单线程 10w+ QPS)
Redis的QPS(每秒查询数)可轻松达到10万级别,延迟通常在1ms以内,远优于传统数据库,核心特性与支撑机制如下:
A. 单线程事件循环:Reactor模式 + 非阻塞I/O(epoll/kqueue/evport/select),高效处理多客户端并发请求;
B. 避免上下文切换:单线程执行所有核心命令,无多线程锁竞争和上下文切换开销,提升执行效率;
C. 零拷贝技术:客户端输出缓冲区直接发送数据,减少数据在用户态和内核态之间的拷贝,提升传输效率;
D. 高效序列化:采用RESP协议(Redis Serialization Protocol),简单文本格式+二进制安全,解析速度快。
核心架构:Reactor事件驱动模型
Redis的高性能核心依赖Reactor事件驱动模型,整体流程如下:
客户端请求 → 多路复用器(epoll) → 事件分发器 → 命令处理(单线程) → 返回结果
多路复用器监听所有客户端连接的I/O事件,当某个连接有事件(如数据到达)时,事件分发器将事件分发到对应的处理模块,由单线程执行命令处理,处理完成后将结果返回给客户端,整个过程无阻塞,高效处理高并发请求。
2. 丰富的数据结构
Redis的核心优势之一是支持多种全栈数据结构,每种数据结构都有针对性的底层实现和算法,兼顾查询效率和内存开销,核心设计思路是通过自适应底层实现(如小数据量用紧凑存储、大数据量用高效查询结构),在不同场景下平衡性能和内存利用率,具体细节可参考“数据结构服务器”模块。
3. 持久化机制
Redis提供RDB、AOF、混合持久化三种方式,核心目标是兼顾数据安全和性能,核心支撑是COW(写时复制)算法和AOF重写机制,确保持久化过程不阻塞主进程服务,具体细节可参考“持久化功能”模块。
4. 高可用与分布式
Redis通过主从复制、哨兵模式、集群模式三层架构,实现高可用和分布式扩展,核心支撑算法包括Raft变种、Gossip协议、CRC16哈希槽分配等,确保集群稳定运行、数据均匀分布、故障自动转移,具体细节可参考“高可用与集群功能”模块。
5. 内存管理与优化
Redis的内存管理机制,核心是“高效利用内存、避免内存溢出”,通过多种算法和策略,优化内存占用和回收效率,具体如下:
A. 过期键删除:采用惰性删除(访问时检查)+ 定期删除(随机采样)的组合策略,平衡CPU占用和内存开销;
B. 内存淘汰:支持8种策略,包括LRU、LFU、Random、TTL等,采用近似LRU算法(随机采样5个取最久未使用),兼顾性能和效果;
C. 内存分配:默认采用jemalloc(可选tcmalloc),支持多种内存大小分配,有效减少内存碎片;
D. 对象编码:根据数据量自动进行编码转换(如ziplist → hashtable),节省小对象内存占用;
E. Intset编码:采用整数集合存储小整数,根据整数范围自动选择int16/int32/int64编码,提升内存利用率。
6. 事务与Lua脚本
Redis通过事务和Lua脚本,实现复杂业务逻辑的原子性执行,具体实现如下:
A. 事务:通过MULTI、EXEC、DISCARD命令,将命令放入队列批量执行,具有原子性(无回滚);同时通过WATCH命令实现乐观锁,监控键的变化,基于CAS(Compare And Swap)语义保证数据一致性;
B. Lua脚本:内嵌Lua解释器,脚本在同一线程内原子执行,支持EVAL/EVALSHA命令,可封装复杂业务逻辑,减少网络开销并保证原子性。
7. 多线程演进(6.0+)
Redis核心命令执行一直采用单线程模型,从6.0版本开始引入多线程优化,主要针对I/O操作,进一步提升网络吞吐能力,版本演进如下:
6.0版本:引入多线程I/O,命令解析和结果写回采用多线程,核心命令执行仍保持单线程,减少I/O阻塞,提升网络吞吐;
7.0版本:优化多线程I/O性能,新增函数库(Functions)持久化,进一步提升Redis的性能和扩展性。
多线程架构流程:
网络读 → 多线程解析 → 单线程执行命令 → 多线程序列化/发送
核心设计思路:保持核心命令单线程执行(避免锁竞争),将耗时的I/O操作(网络读、解析、写回)交由多线程处理,平衡性能和复杂度。
四、Redis核心算法总结
Redis的每一个核心功能和特性,都依赖于高效的算法支撑,这些算法是Redis高效、灵活、高可用的“灵魂”,核心算法及其应用场景如下:
A. 跳表(Skip List):主要应用于Sorted Set的范围查询,实现O(logN)的插入、查询效率,支撑实时排行榜等场景;
B. Radix Tree(基数树):用于Stream消息索引和IP路由表,支持高效的前缀查询和范围查询;
C. LRU/LFU 近似算法:用于内存淘汰策略,筛选需要删除的键,平衡性能和内存利用率;
D. HyperLogLog 概率算法:用于海量数据基数统计(如UV),固定内存占用,允许微小误差(0.81%);
E. GeoHash:用于地理位置索引,将二维经纬度转为一维分数,实现附近地点查询和距离计算;
F. Raft 变种:用于Sentinel领导选举和Cluster故障转移,确保高可用决策的一致性;
G. Gossip 协议:用于集群节点状态传播和故障检测,实现去中心化的集群管理;
H. COW(写时复制):用于RDB持久化和主从全量复制,确保操作期间服务不阻塞;
I. CRC16:用于Cluster槽位计算,将key映射到对应的哈希槽,实现数据分片;
J. 渐进式rehash:用于Hash、Set等数据结构的哈希表扩容,避免一次性扩容阻塞主线程。
五、Redis版本演进
Redis的发展历程中,多个版本推出了里程碑式的特性,这些特性不断完善Redis的功能、性能和扩展性,核心版本的关键特性如下:
2.6版本:引入Lua脚本,支持毫秒级过期时间,提升业务灵活性;
2.8版本:实现PSYNC部分重同步,新增Scan命令,优化主从复制和数据遍历效率;
3.0版本:Cluster集群正式版上线,原生支持分布式分片和高可用;
3.2版本:新增Geo地理位置功能,支持Lua脚本调试,用quicklist替代List旧实现;
4.0版本:引入混合持久化、模块系统、异步删除,提升数据安全和性能;
5.0版本:新增Stream数据类型,完善消息队列功能,支持消费者组和ACK机制;
6.0版本:引入多线程I/O、SSL加密、ACL访问控制,提升网络吞吐和安全性;
7.0版本:新增Functions函数库、Sharded Pub/Sub,优化多线程I/O,进一步提升性能和扩展性。
六、Redis典型应用场景
基于Redis的核心功能和特性,它在实际业务中有着广泛的应用,覆盖缓存、消息、会话、实时计算等多个场景,具体如下:
A. 缓存层:配合TTL过期策略和内存淘汰策略,缓存热点数据(如商品详情、用户信息),缓解后端数据库压力,提升接口响应速度,是Redis最常用的场景;
B. 分布式锁:通过SETNX命令+Lua脚本实现分布式锁,或使用Redlock算法(存在争议),解决分布式系统中多节点并发竞争问题(如秒杀、库存扣减);
C. 限流器:通过Sorted Set实现滑动窗口限流器,或通过Redis Cell模块实现令牌桶限流器,控制接口请求频率,避免高并发请求压垮后端服务;
D. 实时排行榜:基于Sorted Set的跳表结构,实现实时热度排序(如视频播放量、商品销量排行榜),支持范围查询和排名更新;
E. 消息系统:通过Stream数据类型实现复杂消息队列,支持消费者组、消息持久化、ACK确认机制,可替代轻量级MQ,适配中小规模消息场景;Pub/Sub适用于轻量级通知场景;
F. 会话存储:用Hash数据类型存储用户会话信息,设置过期时间自动清理,解决分布式Web系统中会话一致性问题(如电商平台、后台管理系统);
G. 布隆过滤器:通过RedisBloom模块实现,用于概率去重(如用户行为去重、黑名单过滤),避免缓存穿透,提升系统性能;
H. 实时统计:通过Bitmap实现用户签到、在线状态统计,通过HyperLogLog实现UV统计,通过计数器实现文章阅读量、商品销量实时计数;
I. 地理位置服务:基于Geo功能,实现附近商家、附近好友查询,适配外卖、打车、社交等本地生活场景。
七、总结:Redis的高效密码
看到这里,相信大家已经明白:Redis的高效、灵活、高可用,并非偶然,而是“核心定位+功能矩阵+架构设计+算法优化+版本演进”共同作用的结果。
简单总结一下:Redis以“内存数据库+数据结构服务器”为核心定位,构建了覆盖缓存、消息、实时计算、会话管理的全栈功能矩阵;以Reactor事件驱动模型、单线程核心+多线程I/O为架构基础,实现极致性能;以跳表、Raft、Gossip、COW等核心算法为支撑,保障功能的高效实现;通过版本迭代不断完善特性,适配更多业务场景;最终在实际业务中,成为分布式系统、高并发场景中不可或缺的核心组件。
对于开发者来说,了解Redis的核心技术体系,不仅能帮助我们更好地使用Redis(如根据场景选择合适的数据类型、配置最优的持久化和淘汰策略、优化命令执行效率),还能让我们在遇到问题时(如Redis卡顿、内存溢出、集群故障),快速定位根源,找到解决方案。
如果觉得这篇文章对你有帮助,欢迎点赞、收藏,也可以在评论区留言,聊聊你在使用Redis时遇到的问题~