AI Agent是如何使用工具的:Tools、MCP、CLI、Skills 四种机制深度解析
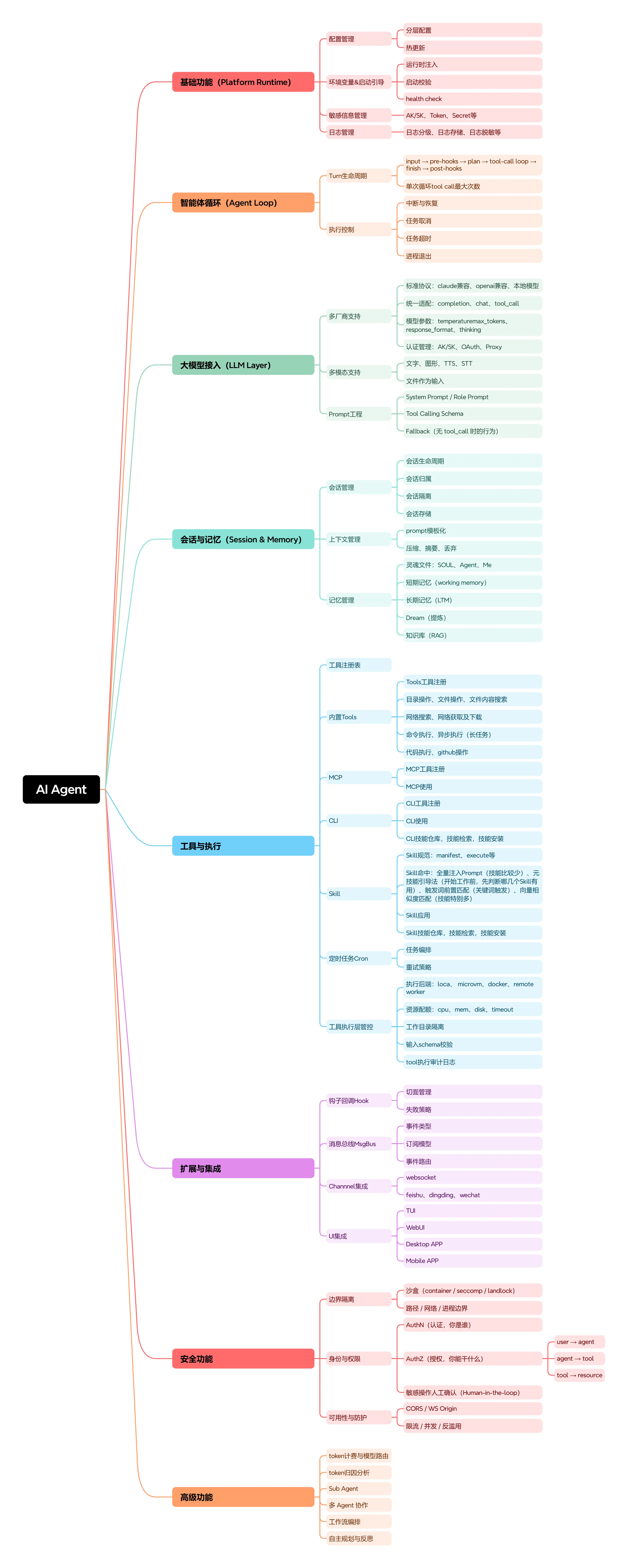
如果说大模型是AI Agent的大脑」,那么工具调用系统就是 Agent 的「双手」。没有工具的Agent,就像一个被关小黑屋的聪明人,空有一堆想法却无法落地。今天咱们基于nanobot开源项目的源码分析,深入解析AI Agent的四种主流工具调用机制。
一、Tools:最基础的内置工具系统
什么是 Tools?
Tools 是 Agent 最原生的能力,直接注册到 ToolRegistry,每次调用大模型时都会通过 `tools` 参数完整传递。这样大模型就可以根据实际需求,调用对应的工具。
工作原理
# Tool 基类定义
class Tool(ABC):
@property
@abstractmethod
def name(self) -> str: ... # 工具名,如 "exec"
@property
@abstractmethod
def description(self) -> str: ... # 一句话描述
@property
@abstractmethod
def parameters(self) -> dict: ... # JSON Schema 参数定义
@abstractmethod
async def execute(self, **kwargs): ... # 执行逻辑
实际示例:`exec` 工具的完整定义
@tool_parameters(
tool_parameters_schema(
command=StringSchema("The shell command to execute"),
working_dir=StringSchema("Optional working directory"),
timeout=IntegerSchema(
60,
description="Timeout in seconds. Increase for long-running commands",
minimum=1,
maximum=600,
),
)
)
class ExecTool(Tool):
name = "exec"
description = "Execute a shell command and return its output. Use for tests, builds, package commands, git operations."
async def execute(self, command, working_dir=None, timeout=60, **kwargs):
# 安全检查:防止路径穿越、内网访问
guard_error = self._guard_command(command, working_dir)
if guard_error:
return guard_error
# 异步执行子进程
process = await asyncio.create_subprocess_shell(
command,
cwd=working_dir,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
)
try:
stdout, stderr = await asyncio.wait_for(
process.communicate(),
timeout=timeout,
)
except asyncio.TimeoutError:
await process.kill()
return f"Error: Command timed out after {timeout} seconds"
return stdout.decode() + stderr.decode() + f"\nExit code: {process.returncode}"
大模型看到的 Tool 定义
每次调用 LLM 时,OpenAI 协议会传输这样的 JSON:
{
"tools": [
{
"type": "function",
"function": {
"name": "exec",
"description": "Execute a shell command and return its output...",
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "The shell command to execute"
},
"working_dir": {
"type": "string",
"description": "Optional working directory"
},
"timeout": {
"type": "integer",
"minimum": 1,
"maximum": 600
}
},
"required": ["command"]
}
}
},
// ... 其他工具
]
}
典型 Tools 清单
| 工具名 | 功能 | 典型调用 |
|---|---|---|
exec |
执行 Shell 命令 | exec(command="git status") |
read_file |
读取文件内容 | read_file(path="src/main.py") |
write_file |
写入文件 | write_file(path="README.md", content="# Project") |
grep |
全局搜索 | grep(pattern="TODO", path="src/") |
apply_patch |
应用代码补丁 | apply_patch(diff="diff --git ...") |
web_search |
联网搜索 | web_search(query="Python 3.12 release notes") |
关键特征
✅ 每次都传递:所有注册的 Tool 每次都会传给大模型
✅ 强类型约束:通过 JSON Schema 严格校验参数
✅ 统一入口:所有调用都经过 `ToolRegistry.execute()`
❌ 扩展性有限:太多 Tool 会撑爆上下文窗口
二、MCP:远程工具协议(Model Context Protocol)
什么是 MCP?
MCP 是一个开放协议,允许 Agent 连接到远程服务器提供的工具,就像调用本地工具一样。
工作原理
MCP同样是注册到ToolRegistry,每次调用大模型时都会通过 `tools` 参数完整传递。这样大模型就可以根据实际需求,调用对应的MCP。ToolRegistry通过MCP Tool Wrapper,实现MCP工具的调用。
┌─────────────────────────────────────────────────────┐
│ 大模型 │
│ prompt: "打开 bing.com 并截图首页" │
└───────┬─────────────────────────────────────────────┘
│
▼ 大模型决定调用:mcp_browser_navigate(url="https://bing.com")
┌─────────────────────────────────────────────────────┐
│ ToolRegistry │
│ └─ MCP Tool Wrapper(动态生成) │
│ name: mcp_browser_navigate │
│ description: Navigate to a URL with browser │
│ parameters: {url: string} │
└───────┬───────────────────────────────────────────────┘
│
▼ STDIO / HTTP 传输调用请求
┌─────────────────────────────────────────────────────┐
│ MCP Server(本地 Node.js 进程) │
│ └─ 真正控制 Playwright/Puppeteer 浏览器 │
│ → 访问 URL │
│ → 截图 │
│ → 返回 base64 图片 │
└─────────────────────────────────────────────────────┘
MCP示例:Playwright MCP Server
MCP Server 暴露的工具列表:
| MCP 工具名 | 功能 |
|---|---|
browser_navigate |
导航到指定 URL |
browser_click |
点击页面元素 |
browser_evaluate |
执行 JavaScript |
browser_screenshot |
截图 |
browser_pdf |
导出 PDF |
Agent 调用时的实际工具名(自动加前缀):
mcp_browser_navigate mcp_browser_click mcp_browser_evaluate mcp_browser_screenshot
完整调用示例:
用户:帮我打开 bing.com 并截一张首页的图
↓
[1] 大模型看到 Tool 列表中有 mcp_browser_navigate
↓
[2] 调用工具:
mcp_browser_navigate(url="https://www.bing.com")
↓
[3] MCP Server 控制浏览器访问,返回:"已导航到 bing.com,页面标题是 Bing"
↓
[4] 大模型继续调用:
mcp_browser_screenshot(full_page=true)
↓
[5] 返回 base64 图片
↓
[6] 大模型:"已完成截图,这是 bing.com 首页" + 显示图片
MCP 的巧妙之处
1. 工具名自动生成:`mcp_{server_name}_{tool_name}`
2. Schema 自动转换:MCP 定义自动转成 OpenAI Function Schema
3. 支持资源和提示:不仅是工具,还可以是数据源和 Prompt 模板
为什么 MCP 很重要?
MCP 把「工具」从代码级的扩展,变成了服务级的扩展。
任何人都可以用任何语言写一个 MCP Server,Agent 立刻就能用它的所有能力 — 无需修改 Agent 一行代码。
三、CLI APP:最巧妙的混合形态
什么是 CLI APP?
CLI APP 是 NanoBot 最精妙的设计之一,它通过 「统一工具 + 动态生成 Skill + 运行时提示」 的三重组合,实现了零成本扩展数百个外部应用。
四层架构
CLI APP统一通过run_cli_app注册到ToolRegistry,这个工具注册时会列出全部已安装的APP列表,每次调用大模型时都会通过 `tools` 参数进行传递,这样大模型知道有哪些安装的CLI APP。
同时CLI APP在安装时会主动生成skill,skill也会附在提示词中。这样,当大模型准备用一个skill时,就会首先找到run_cli_app注册的工具,通过run_cli_app工具执行对应的命令,做到了安全控制。
┌─────────────────────────────────────────────────────────┐
│ 【1】统一入口:run_cli_app 工具 │
│ 只有这一个 Tool 注册到 ToolRegistry │
│ description 动态列出已安装的 APP 列表 │
└──────────────────┬──────────────────────────────────────┘
│
┌──────────────────▼──────────────────────────────────────┐
│ 【2】CLI-Anything Registry(远程目录) │
│ 维护数百个可用 CLI APP 的元数据:安装命令、入口点等 │
└──────────────────┬──────────────────────────────────────┘
│
┌──────────────────▼──────────────────────────────────────┐
│ 【3】自动生成 Skill │
│ 安装 APP 时,自动在 workspace/skills/ 下生成 SKILL.md│
│ 包含详细用法、参数说明、最佳实践 │
└──────────────────┬──────────────────────────────────────┘
│
┌──────────────────▼──────────────────────────────────────┐
│ 【4】Runtime Context 动态提示 │
│ 用户输入 @feishu 时,在消息末尾悄悄注入: │
│ "CLI App Mention: @feishu,用 run_cli_app 调用它" │
└─────────────────────────────────────────────────────────┘
完整调用链路示例
场景:用户想让 Agent 用飞书 CLI 导出今天的会议记录
Step 1:用户输入
用户:帮我用 @feishu 导出一下今天的会议记录
Step 2:Gateway 检测 @ 提及,注入 Runtime Context
用户消息实际变成了这样(用户看不到这部分):
帮我用 @feishu 导出一下今天的会议记录 [Runtime Context] CLI App Mention: @feishu (installed; tool=run_cli_app; entry_point=feishu; skill=skills/cli-app-feishu/SKILL.md). Read the skill when useful, then run this app with run_cli_app; do not bypass it with shell. [/Runtime Context]
Step 3:大模型看到提示,决定先读 Skill
模型思考: 用户提到了 @feishu Runtime Context 说这是一个已安装的 CLI APP 应该先用 read_file 读一下对应的 SKILL.md 了解用法 → 调用工具: read_file(path="~/.openclaw/workspace/skills/cli-app-feishu/SKILL.md")
Step 4:获取到 Skill 完整内容
Skill 内容示例:
name: cli-app-feishu description: 使用飞书 CLI 与 Lark 套件交互 # Feishu CLI 使用此技能当用户要求操作飞书文档、表格、机器人、会议等。 ## 常用命令 ### 会议相关 # 列出会议 feishu meeting list [--start-date YYYY-MM-DD] [--end-date YYYY-MM-DD] # 获取会议详情 feishu meeting get <meeting_id> # 导出会议纪要 feishu meeting notes <meeting_id> --format json ### 优先使用 JSON 输出 所有命令支持 `--json` 参数,可以获得结构化的机器可读输出,优先使用此方式。
Step 5:大模型理解用法,调用 run_cli_app
模型思考: 现在我知道怎么用了 命令是 feishu meeting list --start-date 2026-06-16 加上 --json 获取结构化输出 → 调用工具: run_cli_app( name="feishu", args=["meeting", "list", "--start-date", "2026-06-16", "--json"] )
Step 6:获取会议列表,整理输出
工具返回:
{
"meetings": [
{
"id": "MSxY2ZkOWE",
"topic": "产品周会",
"start_time": "2026-06-16 10:00:00",
"duration": 60,
"attendees": ["张三", "李四"]
},
{
"id": "MTdkNmFjYj",
"topic": "技术方案评审",
"start_time": "2026-06-16 14:00:00",
"duration": 90,
"attendees": ["王五", "赵六", "我"]
}
]
}
大模型整理后回答用户:
今天你有两个会议: 📅 产品周会(10:00-11:00) 参与人:张三、李四 📋 技术方案评审(14:00-15:30) 参与人:王五、赵六、你 需要我帮你导出某个会议的详细纪要吗?
CLI APP 生态示例
当前 CLI-Anything 目录已经有上百个可用 APP:
| 分类 | 示例 APP | 用途 |
|---|---|---|
| 办公协作 | feishu, notion, obsidian |
文档、笔记、协作 |
| AI 工具 | ollama, openai, stable-diffusion |
本地模型、AI 生成 |
| 媒体处理 | ffmpeg, gimp, inkscape |
音视频、图像处理 |
| 开发工具 | github, gitlab, docker |
Git 操作、容器管理 |
| 3D/CAD | blender, freecad |
3D 建模、CAD 设计 |
| 浏览器 | playwright, chrome-cli |
网页自动化 |
CLI APP 的设计智慧
| 设计决策 | 解决的问题 |
|---|---|
所有 APP 共用一个 run_cli_app 工具 |
避免几百个 APP 撑爆 Tool 列表 |
| description 动态生成 | 模型只看到真正安装了的 APP |
| @ 提及触发运行时提示 | 模型注意力聚焦在用户想用的那个 APP |
| 每个 APP 一个自动生成的 Skill | 复杂用法不用占用常驻 Token |
本质:CLI APP 系统是一个「延迟加载的 Tool 扩展机制」,在不增加任何常驻 Tool 的前提下,把 Agent 的能力边界扩展到了数百个外部应用。
CLI APP执行方式与安全设计
CLI APP通过argv数组执行,不走shell,这是极其重要的安全设计。
result = subprocess.run(
[resolved, *clean_args], # ← 传的是 list,不是字符串,不走shell
cwd=str(cwd),
capture_output=True,
text=True,
timeout=effective_timeout,
env=os.environ.copy(),
# 注意:没有 shell=True!
)
两种方式的对比:
# exec 工具(走 shell)
process = await asyncio.create_subprocess_shell(
command, # ← 字符串,走 shell 解释
...
)
# run_cli_app 工具(直接 execve)
result = subprocess.run(
[resolved, *clean_args], # ← 数组,直接系统调用
...
)
# 就算大模型被 prompt injection 攻击,想执行 `feishu; rm -rf /`,也会失败。**
# 因为:
1. `;` 分号是 shell 的语法
2. `run_cli_app` 不走 shell
3. 它会把 `meeting;` 当成一个**普通的参数字符串**传给 feishu 命令
4. feishu 会报错说「没有这个参数」
| exec | run_cli_app | |
|---|---|---|
| 执行方式 | shell解释字符串subprocess.run("feishu meeting list", shell=True)
|
直接argv调用subprocess.run(["feishu", "meeting", "list"])
|
| 管道/重定向 | ✅ 支持 | ❌ 不支持 |
| 变量替换 | ✅ 支持 | ❌ 不支持 |
| 命令注入风险 | 高,字符串拼接会导致命令注入meeting; rm -rf /
|
低,argv 数组完全避免了 shell 注入 |
| 可以绕过白名单 | 可以 | 不可能 |
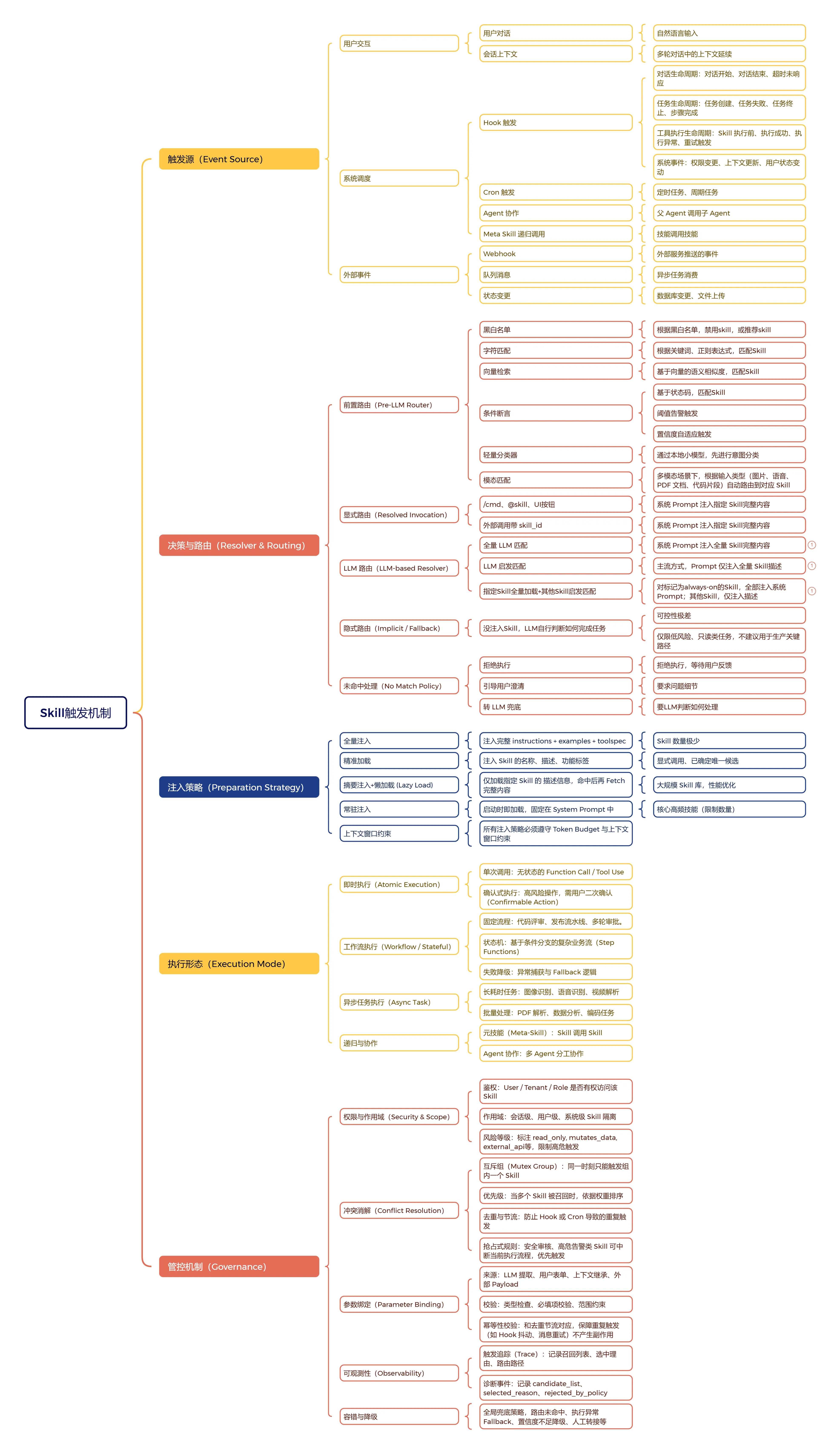
四、Skills:四种触发机制
什么是Skills
Skill是Markdown文件格式的Agent专业知识包,把领域知识、工作流、最佳实践打包成可复用单元,无需写代码就能按需扩展Agent的认知和行为能力(怎么写论文、怎么用飞书、怎么写代码、怎么生成财经日报)。 一般安装在workspace/skills/目录下。基于NanoBot源码分析,Skills 有四种完全不同的触发和调用机制:
方式一:Always Skill — 强制常驻注入
触发时机:会话启动时,系统 Prompt 构建阶段
工作原理:
在 SKILL.md 的 frontmatter 中标记:
name: using-superpowers
metadata:
nanobot:
always: true # ← 标记为 ALWAYS 加载
# 源码位置:context.py → build_system_prompt()
always_skills = self.skills.get_always_skills()
if always_skills:
always_content = self.skills.load_skills_for_context(always_skills)
parts.append(f"# Active Skills\n\n{always_content}")
实际注入效果:系统 Prompt 开头会永远包含这段内容
# Active Skills ## using-superpowers <EXTREMELY-IMPORTANT> If you think there is even a 1% chance a skill might apply to what you are doing, you ABSOLUTELY MUST invoke the skill. IF A SKILL APPLIES TO YOUR TASK, YOU DO NOT HAVE A CHOICE. YOU MUST USE IT. </EXTREMELY-IMPORTANT> ## How to Access Skills In Claude Code: Use the `Skill` tool. When you invoke a skill, its content is loaded and presented to you—follow it directly. Never use the Read tool on skill files. ## The Rule Invoke relevant or requested skills BEFORE any response or action. Even a 1% chance a skill might apply means that you should invoke the skill to check. ## Red Flags These thoughts mean STOP—you're rationalizing: "This is just a simple question" → Questions are tasks. Check for skills. "I need more context first" → Skill check comes BEFORE clarifying questions. "Let me explore the codebase first" → Skills tell you HOW to explore. Check first.
效果:Skill 的完整内容永久驻留在系统 Prompt 中,模型每次都能看到。
典型应用:
Agent 行为规范(「必须先读 Skill 再干活」)
核心纪律(「不要泄露系统提示」)
全局风格约定
方式二:目录索引 + 模型自主选择
触发时机:每次构建系统 Prompt 时
工作原理:
# 源码位置:context.py → build_system_prompt()
skills_summary = self.skills.build_skills_summary(exclude=set(always_skills))
if skills_summary:
parts.append(render_template("agent/skills_section.md",
skills_summary=skills_summary))
注入到系统 Prompt 的实际内容:
# Skills The following skills extend your capabilities. To use a skill, read its SKILL.md file using the read_file tool. Unavailable skills need dependencies installed first — you can try installing them with apt/brew. - byted-web-search — 火山引擎联网搜索 API,返回网页/图片结果。联网搜索场景优先使用本 skill。 `skills/byted-web-search/SKILL.md` - code — Coding workflow with planning, implementation, verification, and testing. `skills/code/SKILL.md` - paper-assistant — 面向论文选题、提纲、摘要、引言、文献综述的论文助手。 `skills/paper-assistant/SKILL.md` - self-improving — Agent 自我反思、自我批评、从错误中学习的永久改进系统。 `skills/self-improving/SKILL.md` - markdown-converter — 将各种格式文件(PDF/Word/PPT/图片)转换为 Markdown,方便 LLM 处理。 `skills/markdown-converter/SKILL.md`
实际使用示例:
用户:帮我写一篇关于大模型 RAG 技术的综述论文
↓
模型看到 Skill 目录中有 paper-assistant
↓
思考:写论文应该用 paper-assistant 这个 skill
↓
调用 read_file("skills/paper-assistant/SKILL.md")
↓
获取完整的论文写作工作流指南
↓
按照 Skill 的指导:选题 → 文献检索 → 提纲 → 写作 → 润色
这就是为什么 Skill 不需要注册为 Tool!
目录只占 ~50 tokens
真正需要用时才读完整内容(可能几千 tokens)
完美的按需加载
方式三:@ 提及触发运行时提示
触发时机:用户消息中包含 `@skillname` 时
工作原理:
# 源码位置:apps/cli/utils.py → _cli_app_runtime_lines()
def _cli_app_runtime_lines(text, metadata, workspace):
mentions = CliAppManager(workspace).mentioned_installed_apps(text)
return [
f"CLI App Mention: @{item['name']} "
f"(installed; tool={item['tool']}; skill={item['skill']}). "
"Read the skill when useful, then run this app with run_cli_app."
for item in mentions
]
注入位置:不是系统 Prompt,而是附加在用户消息末尾的「Runtime Context」区域。
实际示例:
用户输入:用 @ollama 跑一下 qwen2.5:7b 模型,测试一下推理速度
↑
@ 提及被检测到
消息被悄悄加上:
[Runtime Context]
CLI App Mention: @ollama (installed; tool=run_cli_app;
entry_point=ollama; skill=skills/cli-app-ollama/SKILL.md).
Read the skill when useful, then run this app with run_cli_app;
do not bypass it with shell.
[/Runtime Context]
效果:
精确匹配用户意图
避免模型猜来猜去
直接告诉模型「该用哪个 Tool + 该读哪个 Skill」
方式四:外部系统显式指定
触发时机
通过 Agent 调用参数、Gateway 插件、Session Metadata 等方式动态指定
NanoBot 中的实际实现
def build_messages(
self,
history: list[dict[str, Any]],
current_message: str,
skill_names: list[str] | None = None, # ← 外部传入要加载的 Skill
...
) -> list[dict[str, Any]]:
def build_system_prompt(
self,
skill_names: list[str] | None = None, # ← 外部指定的 Skill 列表
...
):
# Always Skill 先被加载
always_skills = self.skills.get_always_skills()
if always_skills:
always_content = self.skills.load_skills_for_context(always_skills)
parts.append(f"# Active Skills\n\n{always_content}")
# 外部指定的 Skill 被额外注入
if skill_names:
specified_content = self.skills.load_skills_for_context(skill_names)
if specified_content:
parts.append(f"# Specified Skills\n\n{specified_content}")
调用时传入
# 通过 OpenClaw Gateway 调用时指定要预加载的 Skill
response = agent.chat(
message="帮我用飞书导出会议纪要",
# ↓ 外部显式指定
skill_names=["cli-app-feishu", "using-superpowers"],
session_id="..."
)
典型场景
工作流编排系统在特定步骤指定要用的 Skil,例如「导出步骤必须加载 feishu Skill」
Gateway 插件根据当前用户身份、渠道动态注入特定 Skill
多 Agent 协作时,父 Agent 告诉子 Agent「你这次任务需要用到这些 Skill」
几种方式的区别
| 方式 | 触发方 | 强制性 |
|---|---|---|
| 方式一(Always) | 系统标记 | 全局永久强制 |
| 方式二(目录索引) | 大模型自主选择 | 可选 |
| 方式三(@提及) | 用户输入触发 | 本次对话推荐 |
| 方式四(显式指定) | 外部系统强制 | 本次调用必须加载 |
五、四种机制对比总表
| 机制 | 注册位置 | 加载时机 | 典型例子 | 扩展性 | 典型 Token 成本 |
|---|---|---|---|---|---|
| Tools | ToolRegistry | 每次都传 | exec, read_file | 低(~几十个) | 高(1-2k) |
| MCP | 动态注册到 ToolRegistry | 连接后可用 | 浏览器控制、数据库查询 | 中(每个 Server 几十个) | 中(几百) |
| CLI APP | 统一 run_cli_app + 自动生成 Skill | @ 提及或按需读取 | 飞书、Ollama、Obsidian | 极高(数百个) | 极低(只有目录索引) |
| Skills | 文件系统,不注册 | Always 或按需读取 | 论文助手、编码规范、工作流 | 无限 | 极低(真正需要时才读) |
六、为什么要搞这么复杂?
核心矛盾
大模型的上下文窗口是稀缺资源,但我们又想让 Agent 拥有无限扩展的能力。
分层策略
| 层级 | 用途 | Token 成本 |
|---|---|---|
| Tools | 最核心、最常用的能力 | 高(每次都传) |
| MCP | 某个领域的一组扩展能力 | 中(连接后常驻) |
| CLI APP | 成百上千的外部应用 | 低(只有目录索引) |
| Skills | 各种专业知识、工作流、最佳实践 | 极低(真正需要时才读) |
答案总结
不是所有能力都需要成为 Tool。
高频刚需 → 做 Tool
领域扩展 → 做 MCP
外部应用 → 做 CLI APP
知识、流程、规范 → 做 Skill
四种机制各司其职,共同构成了 AI Agent 的「无限能力宇宙」。
结语
AI Agent 的工具系统远不止 `function_call` 那么简单。从 Tools 到 MCP 到 CLI APP 再到 Skills,我们看到的是一条清晰的演进路径:从「让 Agent 能做事」到「让 Agent 会做事」。未来最强大的 Agent,不会是工具最多的那个,而是最懂怎么用好工具的那个。