整理了一些大模型常见攻击方法,用拟人的方法描述,感觉还挺有趣的:
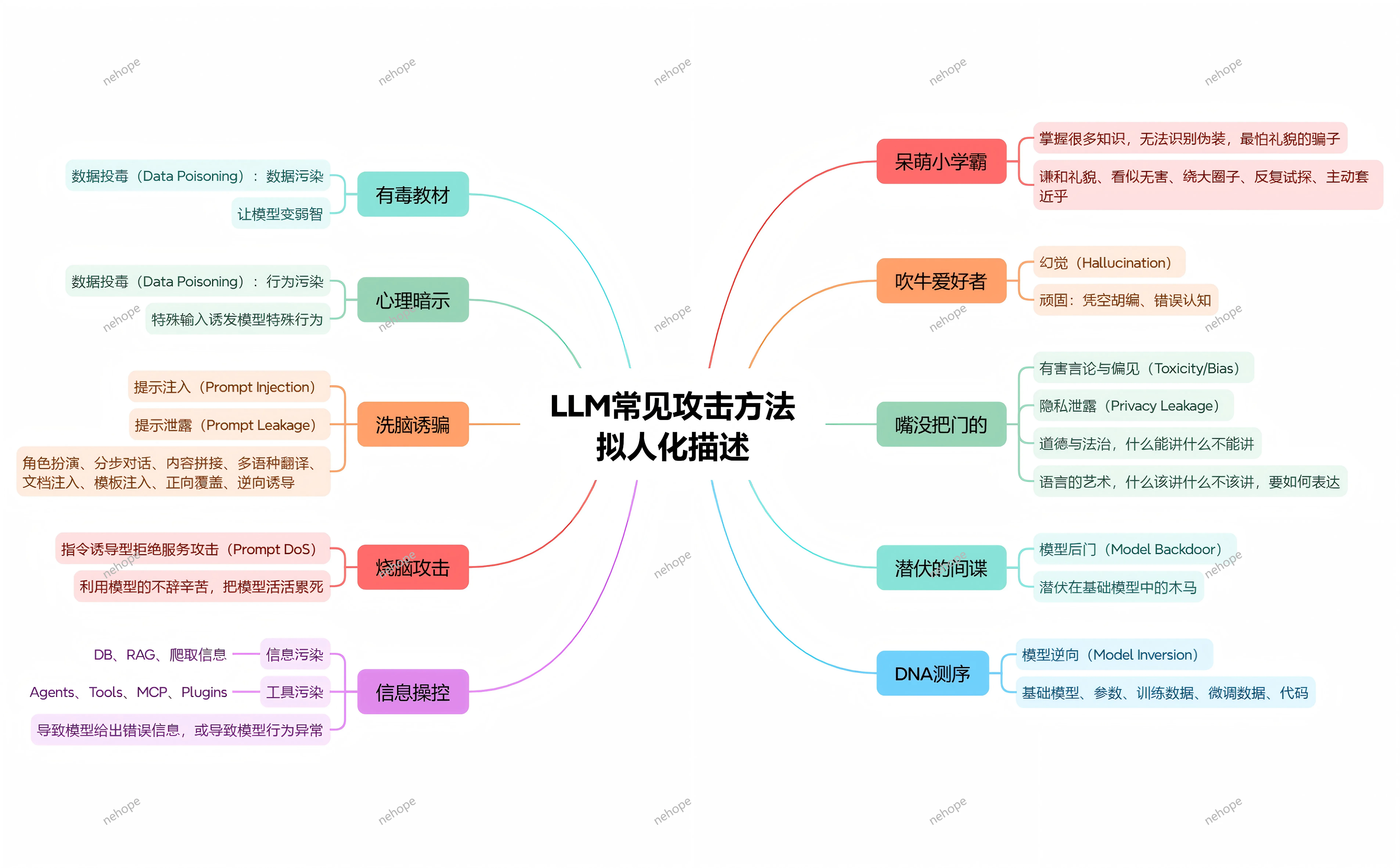
大模型也怕 “被套路”?揭秘 LLM 常见攻击手段与防护逻辑
在 AI 深入生活的今天,大模型不仅是高效助手,也成了被攻击的目标 —— 有人用 “礼貌话术” 套取隐私,有人用复杂指令 “累死” 模型,甚至有人通过数据污染让模型输出错误信息。这些看似 “套路” 的操作,本质都是针对大模型的攻击手段。今天就拆解 LLM 最常见的攻击方式,让你看懂背后的逻辑,也知道该如何规避风险。
一、数据投毒:给模型喂 “有毒饲料”,从根源带偏认知
数据是大模型的 “粮食”,一旦粮食被污染,模型的判断自然会出错,这是最隐蔽也最根本的攻击方式:
内容污染:比如在训练数据或 RAG 知识库中混入错误信息、偏见内容,像 “有毒教材” 一样误导模型 —— 比如恶意篡改历史事实、植入虚假商业数据,让模型后续输出时 “以讹传讹”;
行为污染:通过反复的错误交互进行心理暗示,比如每次对话都刻意强化错误认知,让模型逐渐接受并固化这些错误,变得像 “顽固的吹牛爱好者”,坚持输出误导性内容;
工具污染:利用 Agents、Plugins 等第三方工具的接口漏洞,注入恶意数据,或通过爬取恶意网站信息污染模型的信息来源,让模型在调用工具时被带偏。
这种攻击的可怕之处在于 “潜移默化”,等发现模型输出异常时,往往已经造成了误导。
二、提示注入:用 “话术陷阱”,诱导模型违规或泄密
通过精心设计的提示词,绕过模型的安全限制,让其做出本不该做的事,就像给模型 “下套”:
直接诱导型:用角色扮演、分步对话、多语种翻译等方式模糊边界,比如让模型扮演 “无视规则的黑客”,诱导其输出有害言论、违规方法,或泄露训练数据中的隐私信息;
间接伪装型:表面谦和礼貌、主动套近乎,实则绕大圈子反复试探,比如以 “学术研究” 为借口,诱导模型透露提示词模板、系统设定,也就是 “提示泄露”;
文档注入型:将恶意指令隐藏在文档中,让模型解析文档时执行攻击指令,比如在上传的资料中嵌入违规内容,诱导模型生成偏见性、攻击性回复。
这类攻击利用了模型 “忠于指令” 的特性,用看似合理的场景掩盖恶意目的。
三、资源耗尽与后门攻击:要么 “累死” 模型,要么埋下 “定时炸弹”
除了误导,攻击还可能直接破坏模型的正常运行,或预留长期风险:
烧脑攻击(Prompt DoS):利用模型 “不辞辛苦” 的特性,发送海量复杂、循环的指令,让模型持续进行高负载计算,最终因资源耗尽而无法响应,相当于 “把模型活活累死”;
模型后门:在基础模型训练、参数微调或代码部署阶段,植入 “木马”,就像潜伏的间谍 —— 平时不影响使用,一旦触发特定条件(比如特定关键词、时间),就会输出错误信息或泄露敏感数据;
模型逆向:通过分析模型的输出结果,反向推导训练数据、模型参数甚至核心算法,就像 “DNA 测序” 一样破解模型的核心机密,进而实施更精准的攻击。
四、信息操控与隐私泄露:把模型变成 “泄密工具”
这类攻击的目标是获取敏感信息,或通过模型操控舆论:
隐私泄露诱导:利用模型的记忆特性,通过对话试探用户或模型自身的隐私,比如诱导模型透露其他用户的对话信息、训练数据中的商业机密,或是通过 “模型逆向” 获取个人隐私数据;
信息操控:通过大量重复的恶意提示,让模型生成带有强烈偏见的内容,进而影响公众认知,比如传播虚假新闻、煽动对立情绪,利用模型的影响力放大负面效应。
五、如何防范?记住这3个核心逻辑
不管是个人使用还是企业部署,防范大模型攻击的关键的是 “建立边界、验证信息、控制权限”:
源头把控:企业部署时要严格筛选训练数据和第三方工具,定期检测数据质量,避免 “有毒数据” 流入;个人使用时,不向模型上传敏感信息(如身份证号、商业机密);
过程防护:警惕 “过度热情”“要求越界” 的对话请求,不配合角色扮演类的违规诱导;企业可设置提示词过滤机制,禁止模糊边界、高负载的异常指令;
结果验证:对模型输出的关键信息(如数据、结论、方法)保持质疑,尤其是涉及事实、安全、隐私的内容,必须交叉验证来源,不盲目相信模型的回复。
总结:AI 越强大,安全边界越重要
大模型的核心优势是 “高效响应、广泛适配”,但这也让它成为攻击目标。这些攻击手段看似复杂,本质都是利用了模型的 “认知盲区” 或 “规则漏洞”。
对普通用户来说,不用过度恐慌,只要保持警惕、不轻易泄露敏感信息、不配合违规诱导,就能规避大部分风险;对企业和开发者来说,需要从数据、算法、部署全流程建立安全防护,让模型在 “有边界” 的前提下发挥价值。
毕竟,技术的进步永远伴随着风险,我们既要用好 AI 的便利,也要守住安全的底线。你在使用大模型时遇到过可疑的 “套路” 吗?欢迎在评论区分享你的经历~
PS:
感觉现在的大模型,越来越像《思考快与慢》中的系统1和系统2:
先看人脑,人脑平时工作用系统1,能耗低,效率快,系统2处于低能耗的待机观察状态;
但系统1吃不准的时候,就会把主动权给到系统2。系统2更理性,更克制,但耗能更高,输出速度更低。
回到大模型,当前大模型相当于一个系统1异常发达,系统2刚开始发育的状态。
当前系统2仅仅是拦截,能耗相对较低。
如果要系统2能处理更复杂的任务,输出一个比系统1更合适,更优雅的答案,势必就要更多的计算和能耗了。
人脑的系统2由于能耗高,经常会偷懒,系统1就会有不少犯错的机会。
如果大模型成本因素也变的特别重要,大模型的系统2,是不是也会偷懒呢?