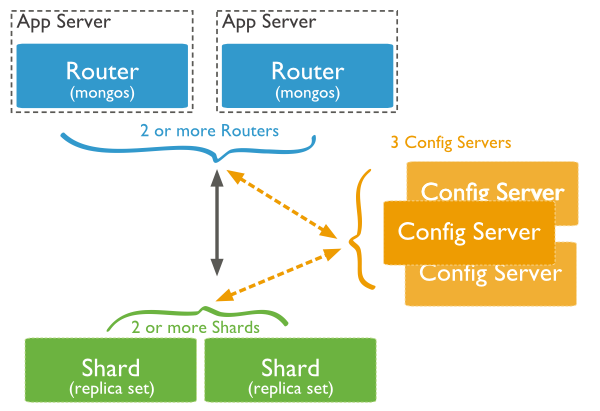
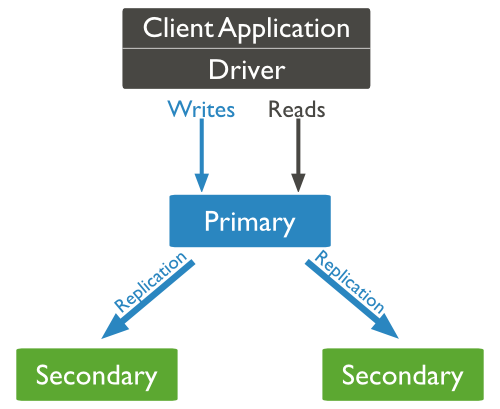
0、数据准备
for(var i=0;i<10000;i++){
var patid="pat"+i;
var patname="name"+i;
var sex="M";
var age=parseInt(100*Math.random(i));
db.patient.insert({"patid":patid,"patname":patname,"sex":sex,"age":age,address:{"city":"shanghai","street":"huaihai road"}});
}
1、比较运算符
| 运算符 | 操作符 |
| > | $gt |
| >= | $gte |
| < | $lt |
| <= | $lte |
| != | $ne |
| = | $eq 或 空 |
db.patient.find({"age":20})
db.patient.find({"age":{$eq:20}})
db.patient.find({"age":{$ne:20}})
db.patient.find({"age":{$gt:20}})
db.patient.find({"age":{$gte:20}})
db.patient.find({"age":{$lt:20}})
db.patient.find({"age":{$lte:20}})
2、逻辑运算符
| 运算符 | 操作符 |
| And | $and |
| Or | $or |
db.patient.find({$and:[{"age":10},{"age":11}]})
db.patient.find({$or:[{"age":10},{"age":11}]})
3、IN 与 Not IN
| 运算符 | 操作符 |
| In | $in |
| not in | nin |
db.patient.find({"age":{$in:[10,11]}})
db.patient.find({"age":{$nin:[10,11]}})
4、where
db.patient.find({$where:function(){return this.patid=='pat1000'}})
db.patient.find({$where:function(){return this.patid=='pat1000' || this.age==1}})
5、正则表达式
#patid以0做结尾
db.patient.find({"patid":/0$/})
#patid以pat开头
db.patient.find({"patid":{$regex:"^pat"}})
#patid以pat开头,切不区分pat大小写
db.patient.find({"patid":{$regex:"^pat",$options:"$i"}})
#patid以pat1做开头,age为10
db.patient.find({"patid":/^pat1/,age:10})
6、分页与排序
db.patient.find({"patid":/0$/}).count()
db.patient.find({"patid":/0$/}).limit(10)
db.patient.find({"patid":/0$/}).skip(10).limit(10)
db.patient.find({"patid":/0$/}).sort({"age":1})
db.patient.find({"patid":/0$/}).sort({"age":-1})
7、between是由min max来实现的
#需要age字段的索引哦
db.patient.find({"patid":/0$/}).min({"age":10}).max({"age":20})
8、全文检索
#建立text索引后,mongo会帮你分词,一个collection只能建立一个text索引
#在patname字段建立全文索引
db.patient.ensureIndex({"address.street":"text"})
#在全部字段建立全文索引
db.patient.ensureIndex({"$**": "text"})
#进行简单查询
db.patient.find({$text:{$search:"huaihai"}})