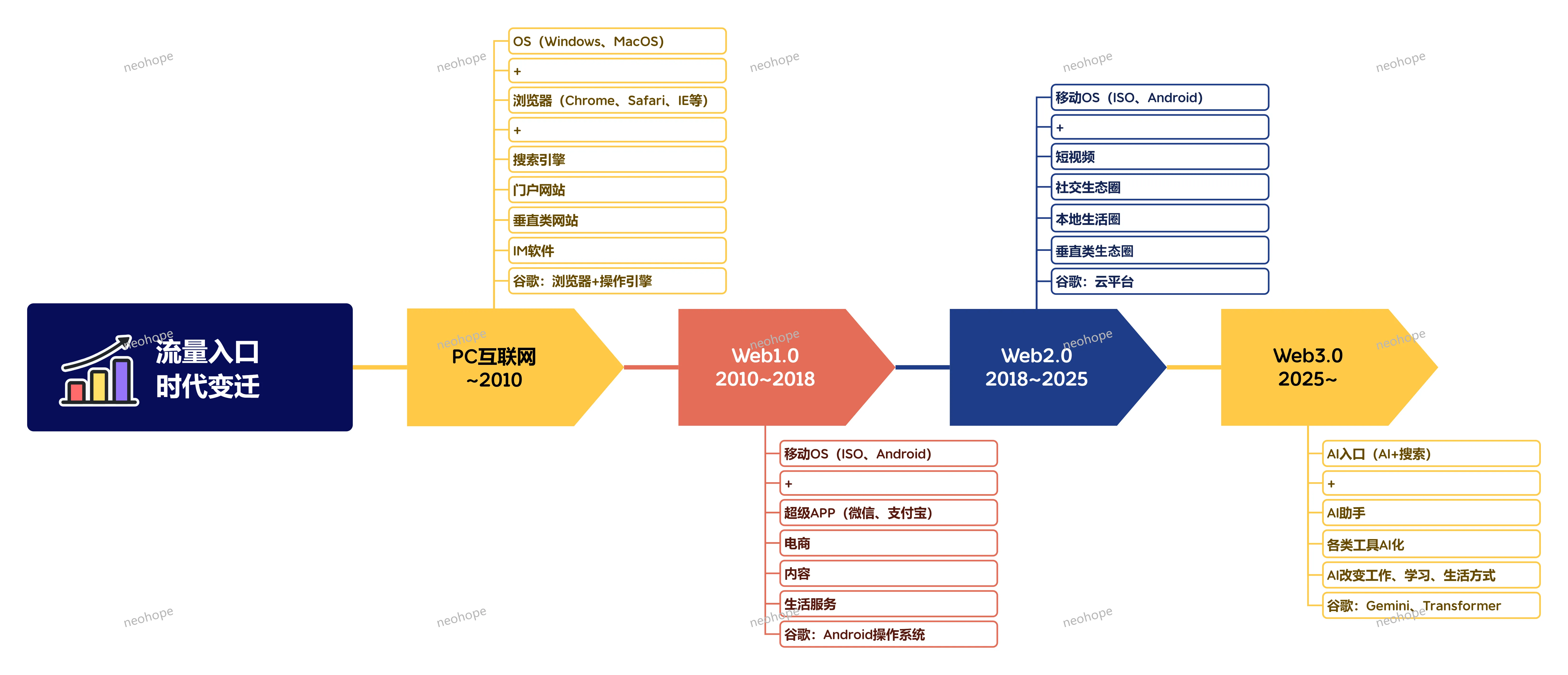
常见软件服务收费模式:
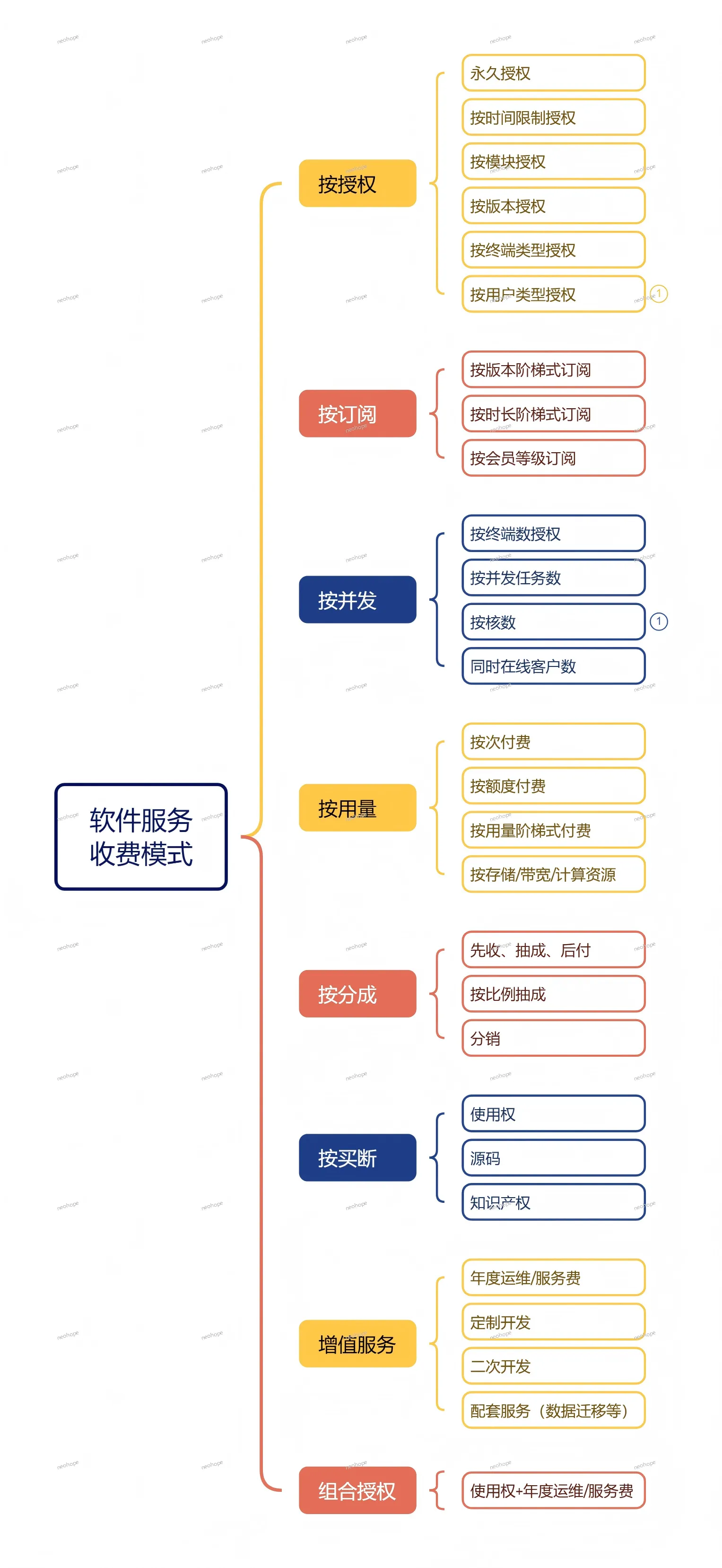
一文理清软件服务收费模式:从授权到订阅,企业该怎么选?
做企业数字化选型时,最头疼的往往不是功能匹配,而是五花八门的收费模式。“永久授权和按年订阅哪个更划算?”“按终端数收费和按并发数收费有啥区别?” 其实软件服务的收费逻辑本质是 “价值匹配”—— 不同模式对应不同的使用场景,今天就把常见的收费模式拆清楚,帮你避开选型陷阱。
先说说最基础的授权类收费,这是很多传统软件的主流模式。核心分两类:一是永久授权,一次性付费买断使用权,甚至能拿到源码和知识产权,适合长期使用、需求稳定的企业,比如内部核心业务系统,一次投入终身受益(但要注意后续运维成本);二是有限制授权,比如按时间限制(月度 / 年度授权)、按终端类型(PC 端 / 移动端分开授权)、按用户类型(管理员 / 普通用户差异化收费),这种模式灵活度高,适合短期试用或阶段性需求。
还有一类细分的授权模式,精准匹配 “按需使用” 需求:按模块授权(只买需要的功能模块,避免为冗余功能付费)、按版本授权(基础版 / 专业版 / 企业版阶梯定价)、按终端数授权(多少台设备使用就付多少费用)、按并发任务数 / 核数 / 同时在线客户数收费(资源占用越多,费用越高,适合高频使用场景)。这类模式的核心是 “用多少付多少”,能最大程度降低企业初期投入。
再看现在越来越流行的订阅类收费,主打 “持续服务 + 灵活调整”。最常见的是按版本阶梯式订阅(不同版本对应不同订阅价格,随需求升级)和按时长阶梯式订阅(订阅周期越长,单价越低,比如年付比月付划算);还有按会员等级订阅(VIP 会员享受更多增值服务),适合需求迭代快、希望持续获得技术支持的企业。订阅制的优势在于把一次性大额支出变成小额分期,还能随时根据业务规模调整,降低试错成本。
除了核心使用费用,按用量付费也成了云服务时代的热门选择。比如按次付费(使用一次结算一次,适合低频刚需场景)、按额度付费(预存费用按实际使用抵扣)、按存储 / 带宽等资源付费(云计算常用模式,资源弹性伸缩),还有更灵活的按用量阶梯式付费(使用量越多,单价越低,鼓励长期深度使用)。这种模式完全贴合 “使用多少、付费多少” 的逻辑,特别适合业务波动大的企业。
另外还有两类容易被忽略的收费模式:一是分成类,比如先使用后付费、按比例抽成、分销分成,适合轻资产创业公司或与软件方共建业务的场景;二是配套服务类,比如年度运维服务费(保障软件稳定运行)、定制开发费(根据企业需求个性化开发)、二次开发费(在原有基础上扩展功能)、数据迁移费等,这些 “隐性成本” 往往决定了软件后续的使用体验,选型时一定要提前确认。
最后总结一下:如果需求稳定、长期使用,优先选永久授权;如果需求多变、想控制初期投入,订阅制或按用量付费更合适;如果是短期项目或低频使用,按次付费、按时间限制授权更划算。关键是要根据自身业务规模、使用频率、功能需求,找到 “价值与成本” 的平衡点,避免盲目追求低价而忽略后续服务,也不要为用不上的功能支付额外费用。
你在软件选型时遇到过哪些收费模式的困惑?欢迎在评论区留言交流~