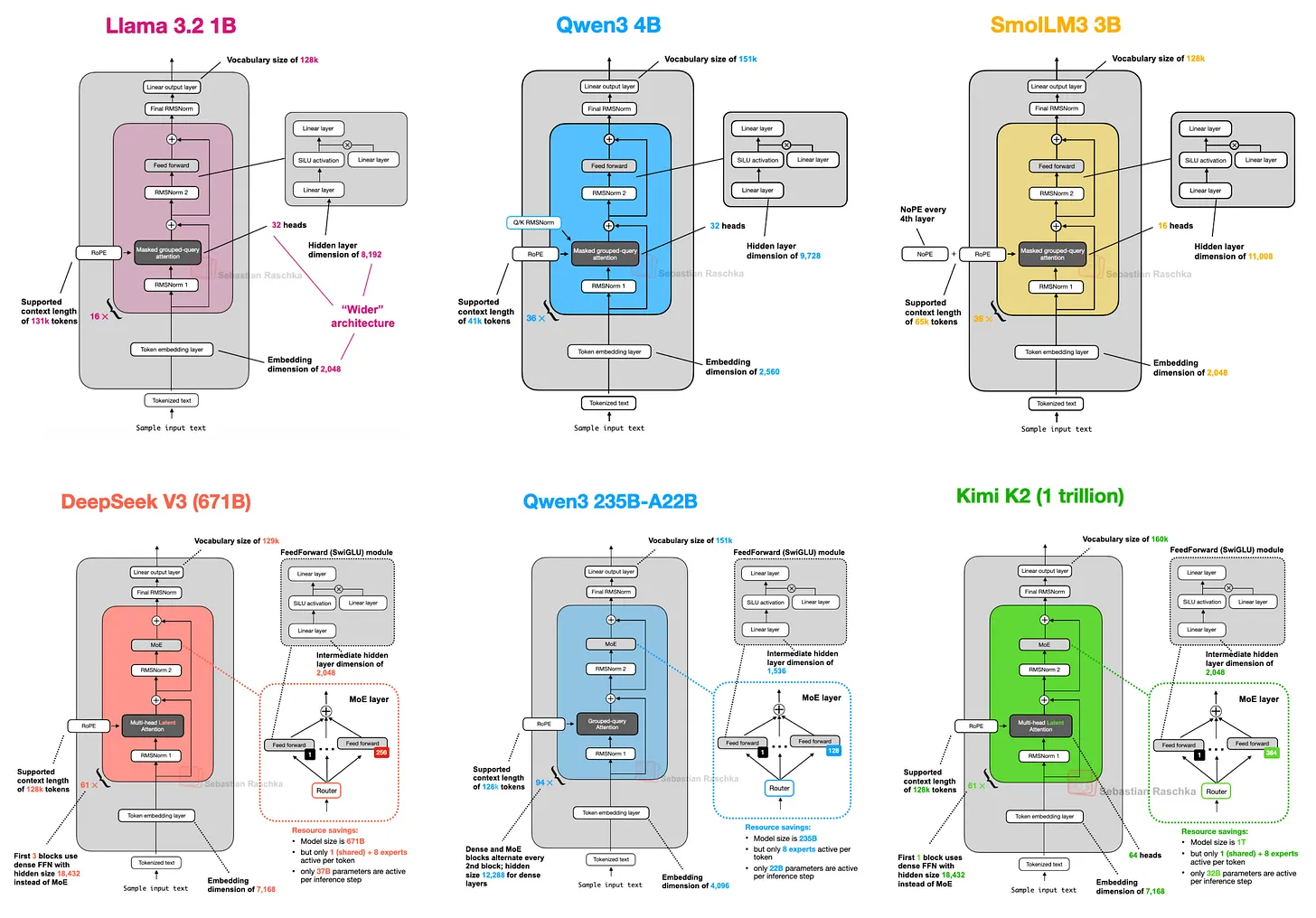
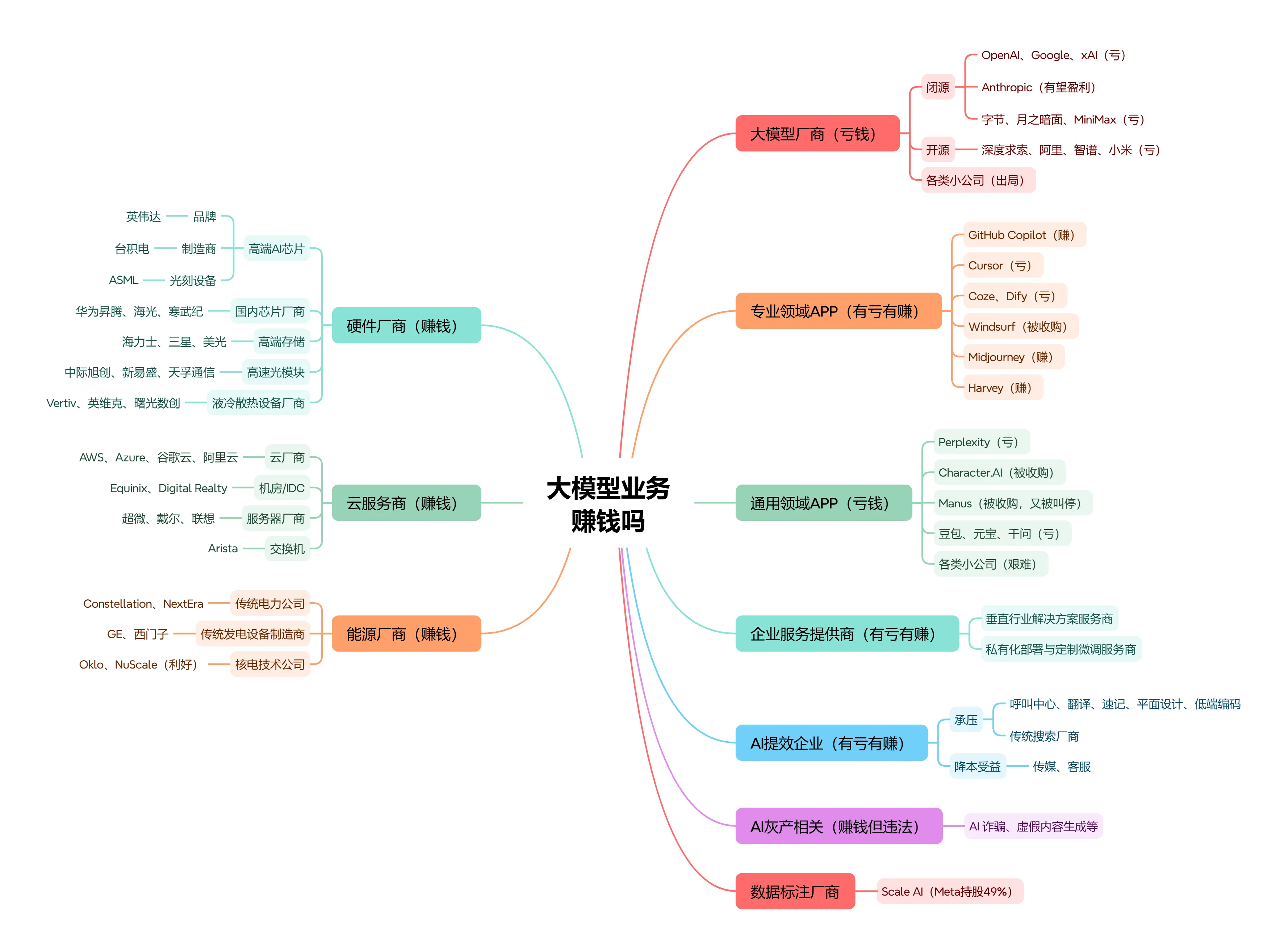
Agent购物带来新挑战:当决策入口与履约剥离,电商的底层逻辑正在被彻底改写
近期各大电商陆续开始提供AI购物功能,各大AI平台也开始提供比价甚至购物功能(国内生态比较封闭,第三方购物Agent反而是国外走到了前列)。当你对着 AI 助手说一句 “帮我选一款千元以内无线降噪半入耳耳机,明天能送到”,就能直接收到下单确认时,你可能没意识到:电商行业运行了二十年的商业规则,正在被悄然拆解。
Agentic Commerce(代理式电商)不是货架电商、兴趣电商之后的一次界面升级,它的真正冲击力,不在于 “大家以后都不打开 App 了”,而在于它把 “决策入口” 和 “履约 / 供应链” 两层彻底剥开了。AI Agent 作为新的中间层拿走了筛选与决策的权力,传统平台则逐步退化为供给与履约的后端服务商。短期看传统投流、直播不会被颠覆,但标品、复购品的营销效用会被显著削弱;中长期看,谁握有 “AI 愿意调用” 的供给与履约能力,谁就握有了新的行业议价权。
一、入口与履约的剥离:电商底层逻辑的断裂
Agent 购物的本质,是在消费者和零售商之间插入了一个全新的决策中间层 ——AI 代理自主完成参数读取、跨平台比价、自动下单全流程。摩根士丹利研报预测,到 2030 年 AI 购物代理可为美国电商市场带来最高 1150 亿美元的增量消费,基准情景下将占据 10% 的线上零售份额,乐观情景下可达 20%。但报告同时明确指出:拥有强大基础设施、独特库存的零售商(亚马逊、沃尔玛)将成为赢家,而依赖高抽成和搜索流量的平台则会面临直接挑战。
映射到国内市场,这种冲击体现在三个核心层面:
1. 流量分发权被重新分配,注意力广告根基动摇
过去二十年的电商是 “人找货” 的逻辑 —— 用户在搜索框输入关键词、在列表页筛选,平台通过控制这个入口向商家收取广告费。支撑这套模式的,是全球近 2000 亿美元规模的零售媒体广告市场,搜索排名、首页展位、信息流推广,本质都是向商家售卖用户的浏览注意力。
Agent 进来后,决策主体从人变成了 AI:AI 读取结构化参数和数据做决策,不会被主图噱头吸引,不会因排名靠前就优先选择。建立在 “吸引人类眼球” 基础上的零售媒体广告模式正在发生根本性变化,平台可能从用户交互的前台,退化为 Agent 调用的后端服务。
2. 广告竞价体系的底层逻辑被直接撼动
电商平台的核心利润来源 —— 直通车竞价排名、坑位费、流量广告,本质是 “注意力税”。而 Agent 是绝对理性的比价机器,会瞬间穿透营销包装,把流量导向极致性价比的标品,直接冲击平台赖以生存的广告竞价体系。
对于高度标准化的品类,这种冲击尤为显著:3C 家电、日用品、包装食品等参数清晰的商品,用户会直接委托 Agent 比价下单,不再手动浏览页面,对应的搜索广告、展示广告价值会持续缩水。
3. 履约壁垒反而被强化:平台不会消失,只会分化
一个关键的事实常常被忽略:Agent 能替你决策,但不能亲自把饭送到门口,不能凭空变出骑手和仓库库存。外卖表面是信息生意,本质是履约生意 —— 商户密度、骑手规模、实时调度系统、线下运营能力,这些 “物理世界的密度” 无法被大模型瞬间复制。
所以更准确的判断是:AI 抽走了前端的决策入口,但后端的履约能力反而会强化头部平台的壁垒。纯流量型平台会面临巨大的入口替代风险,而重资产、强履约的平台,反而会成为 AI 时代的基础设施。
4. 封闭生态的囚徒困境:“伪全网比价” 的现实尴尬
目前国内各家平台的 AI 购物,并没有实现真正的 “全网比价”。实测显示,千问优先推荐淘宝天猫商品、豆包定向引流抖音商城、京东 AI 购主推自营货品,本质都是 “套了大模型外壳的站内搜索”。
平台陷入了典型的囚徒困境:开放全量数据对消费者体验最好,但对自身流量护城河最致命;封闭生态则会消解 Agent 购物的核心价值。这种集体选择的 “围墙花园” 策略,也导致当前 AI 购物体验与用户预期落差巨大 —— 海外调研显示,近七成的用户在收到无关推荐后会直接放弃使用,转而回到传统搜索方式。
二、被高估的 “客观”:Agent 没有消灭偏见,只是换了一种偏见
很多人认为 Agent 购物至少比人类更客观 —— 它不会被直播逼单忽悠,不会被品牌故事洗脑,只会理性对比参数。这句话只对了一半:Agent 确实能过滤人类的情绪偏差,但它同时引入了全新的 AI 决策偏差,甚至在某些维度上比人类更容易被针对性操纵。
1. “去营销化” 的优势真实存在
在过滤情绪型、套路型营销上,Agent 的价值毋庸置疑:
-
它会直接跳过主图噱头、详情页情怀、限时焦虑营销,只提取核心参数、价格、履约、售后等结构化信息;
-
它能自动在同价位、同定位的商品池中做参数对齐,避免厂商 “田忌赛马” 式的错位宣传;
-
它可以在几秒内读完数千条评价,自动提取差评集中的共性问题,比人类手动翻页的效率与全面性高出数个量级。
对于高度标准化的标品,Agent 在排除情绪干扰、提升决策效率上的优势非常明显。
2. 纸面参数≠真实体验,注水空间依然存在
Agent 只能识别可量化的纸面指标,无法判断实际使用体验。厂商完全可以针对性 “优化参数”:手机标注支持 100W 快充但标配 67W 充电器,家电标注一级能效但日常工况耗电更高,护肤品标注成分浓度却不说明活性与吸收率。
对于服装、食品、家居等非标品,本身就没有统一的参数标准,Agent 只能依赖商家打标签和用户评价做判断,反而更容易被关键词堆砌的营销内容误导。
3. 销量与评价,反而成了 AI 时代的新型作弊工具
人类看评价能通过语气、配图、追评时间分辨刷评痕迹,而目前大多数购物 Agent 主要做语义关键词提取,对 “高质量刷评” 的识别能力远弱于人类。
市场上已经出现了专门面向 AI 的刷评服务:商家组织刷手刻意堆砌 AI 偏好的正面关键词,反而能提升商品在 AI 推荐中的权重。同理,销量、店铺评分都可以通过刷单拉高,AI 会把这些注水数据当成 “受欢迎” 的依据,进一步放大虚假优势。
4. 大模型自带偏见,营销从 “前台” 转到了 “后台”
Agent 的底层大模型在训练时已经吸收了全网的品牌公关稿、营销内容、媒体报道,品牌知名度与口碑沉淀会天然影响推荐优先级。过去厂商投广告是影响用户心智,现在做品牌公关、铺全网内容是影响大模型的认知,本质还是营销,只是受众从人变成了模型。
更直接的偏差来自平台立场:绝大多数平台自带的购物 Agent 都有利益倾向 —— 优先推荐自营商品、高佣金商品、合作品牌商品。这种商业排序下的推荐,本质是平台利益优先,而非客观最优。
三、传统营销的冲击:标品广告失效,内容与品牌价值重构
传统投流、广告、直播不会彻底消失,但会出现剧烈的场景分化:在标准品、复购品、价格敏感决策上效用显著下降;在非标品、内容触发、品牌建设上依然有不可替代的价值,但形态会持续进化。
1. 效用显著下滑的三类场景
-
标准品的比价广告:3C 家电、日用品、奶粉等参数清晰、可量化比较的品类,Agent 会直接按性价比排序,Banner 广告、直通车竞价排名的有效性会持续走低。
-
冲动消费触发:限时秒杀、“砍一刀” 这类依赖人性弱点的玩法,对 “最不冲动的决策者” Agent 几乎无效,对应的流量变现逻辑会逐步失灵。
-
短链路种草转化:传统的 “看笔记→被种草→直接下单” 链路会被截断 —— 用户让 Agent 买护肤品,它会去查成分、比价格、看差评,而不是被一篇素人笔记打动完成冲动消费。
2. 依然不可替代的价值阵地
-
品牌曝光与心智建设:直播间、达人种草、短视频内容在 “制造欲望” 这件事上仍然不可替代。用户依然需要内容来发现新品、建立审美、产生消费冲动,再由 Agent 完成后续的比价与下单。抖音这类兴趣电商平台,在这个环节依然拥有核心优势。
-
非标品与情感消费:服装、美妆、家居、文旅等需要 “逛” 和 “感知” 的品类,消费决策包含审美、情绪、体验属性,人类手动购物仍是主流,Agent 只能起到辅助作用。
-
商家侧 AI 提效工具:阿里妈妈 “AI 万相”、京东 “京小通”、AI 数字人直播等工具正在快速普及,推动AI能力从C端入口向B端运营提效延伸,这部分的营销预算反而在快速增长。投手的角色从 “执行者” 转向 “策略制定者 + AI 训练师”。
3. 营销的新战场:GEO 正在崛起
广告预算不会消失,只会从 “人眼曝光” 流向新的方向 ——GEO(Generative Engine Optimization,生成引擎优化,也被称为 AEO,AI 引擎优化),也就是学会 “取悦机器”,让 Agent 在回答时优先推荐自己。
商家的运营重心正在发生系统性转移:
-
从优化主图点击率,转向优化商品结构化参数,统一行业标准口径,方便 AI 提取识别;
-
从引导用户快速下单,转向引导真实用户留下 AI 偏好的评价关键词,提升商品在 AI 排序中的权重;
-
从投放平台流量广告,转向完善商品知识库,主动向大模型提供官方、准确的产品信息;
-
从打造短期爆款,转向沉淀品牌全网声量,强化大模型对品牌的正面认知。
厂商不再需要说服人类消费者,但需要说服 AI Agent。话术从 “打动用户” 变成了 “符合 AI 排序规则”,营销的底层逻辑没变,只是战场变了。
四、平台梯队重塑:谁在 Agent 时代掌握了新议价权
Agent 时代,电商平台的核心竞争力从 “流量运营能力” 转向了供给确定性、履约壁垒、数据结构化程度与自有 AI 入口闭环能力。国内平台已呈现清晰的梯队分化,不同模式的平台命运截然不同。
| 平台 |
Agent 时代的定位 |
核心优势 |
主要风险 |
| 阿里 |
全链路 AI 购物入口 |
全品类 + 支付 + 物流 + 千问闭环 |
核心利润来源(广告)被 Agent 直接冲击 |
| 京东 |
Agent 优选的供应链底座 |
自营履约确定性强、3C 家电品类优势 |
商家生态相对封闭、入口依赖腾讯生态 |
| 美团 |
本地生活履约管道 |
千万级商家网络、骑手调度体系 |
前端入口价值被抽走,面临管道化压力 |
| 抖音 |
内容驱动的 AI 购物闭环 |
用户时长最长、内容生态最丰富 |
广告模型与 Agent 逻辑存在天然冲突 |
| 拼多多 |
低价标品的 Agent 优选 |
白牌低价天然匹配比价逻辑 |
冲动消费变现模式逐步失效 |
| 小红书 |
内容社区(种草电商) |
种草心智依然稳固 |
种草→转化的链路被 Agent 截断 |
阿里 —— 全链路闭环暂时领先半个身位
千问 + 淘宝闪购 + 饿了么 + 支付宝的全链路组合,是当下国内最完整的 AI 购物生态。阿里投入数百名算法工程师,将淘宝二十年的电商能力转化为千问可调用的技能库,内测数据显示,“AI 店小蜜 + 人工” 的组合转化率已实现全天候超越纯人工客服。
但隐患也同样突出:淘天的收入核心是竞价排名,本质是纯粹的注意力税,而 Agent 冲击最直接的正是这块利润基本盘;且千问只能检索淘宝生态内商品,“伪开放” 的争议会影响长期用户信任。
京东 —— 模式最安全,但入口偏弱
京东是被 Agent 冲击最小的传统电商 —— 因为它的核心利润来自进销差价而非广告费,重资产的物流体系恰好是 Agent 最信任的参数:履约确定性。
目前京东 AI 超脑大模型已覆盖上千个核心业务场景,同时与腾讯元宝打通小程序生态,拿下了微信 AI 原生的对话流量,对 3C 家电等决策型长周期商品的转化尤其有利。“服务封装一次、多渠道输出” 的开放路线,正在成为它对抗流量焦虑的核心策略。
短板在于第三方商家丰富度不足,且 “自营 = 放心” 的品牌溢价会被逐步压薄 —— 当 Agent 能独立验证任何渠道的商品可靠性时,平台的品牌招牌溢价会持续收窄。
美团 —— 履约壁垒深厚,但前端入口被抽走
美团是被 Agent 重构最明显的超级平台,但不会被消灭。
它的护城河在物理世界:千万级商家网络、数百万骑手体系、毫秒级实时调度系统,这些都是 AI 无法瞬间复制的硬壁垒。但用户习惯 “用 AI 点外卖” 后,美团会从超级 App 退化为本地生活履约核心,失去前端定价权与流量溢价。
王兴提出的 “To A” 战略,自研 “小美” Agent 并与腾讯元宝深度合作,本质是试图成为 “所有 Agent 背后的履约管道”。但管道化的代价也很明显:参考高强度的线下运营属性,其估值逻辑可能从高增长互联网平台向稳健的零售/物流基础设施靠拢,市盈率中枢或将下移。
抖音
豆包是国内 C 端用户时长和流量最强的 AI 入口之一,“豆包帮你选 + 抖音电商内容种草” 的闭环是独特路径。但隐患在于,当前广告模型依赖 “打断 + 情绪触发”,这正是 Agent 最先接管的场景;且供应链与履约能力依然是短板。
拼多多
白牌、极致低价的货盘,跟 Agent 的比价优化目标天然契合,在价格敏感型需求中是天生赢家。但它的变现高度依赖广告,流量玩法高度依赖冲动消费,而 Agent 是 “最不冲动的顾客”,长期变现逻辑承压。
小红书
核心价值是 “种草”,用内容制造欲望再完成转化。Agent 进来后这个链路被直接截断,电商转化率会持续承压,是主流平台中受冲击最直接的一家。
亚马逊
自营商品 + FBA 全球履约网络 + Alexa 语音入口,和京东的逻辑高度相似,凭借供给确定性成为 Agent 时代的核心赢家。
Shopify
不做流量竞争者,而是做 AI 时代的卖水人。推出 Agentic Storefronts 功能,一键对接所有主流 AI 入口,帮助商家接入全渠道 AI 流量,反而在浪潮中直接受益。
五、新的挑战者:中立第三方 Agent 的降维打击
一个容易被忽略的判断是:Agent 时代的真正赢家,可能不是任何一家电商平台,而是与平台利益无关的第三方中立 Agent。
平台自有 Agent 天然背负着 “屁股决定脑袋” 的原罪:它要优先推荐自营商品、高佣金商品、合作品牌,永远无法做到绝对中立。而第三方 Agent 没有广告主、没有佣金池,唯一的商业模式是让用户觉得它可靠、公正。对用户而言,更换一个 Agent 的成本趋近于零,信任会成为最核心的竞争壁垒。
当用户养成了 “先问中立 Agent,再决定去哪里买” 的习惯,所有平台自有 AI 入口都会沦为二级选项。这才是传统电商平台真正要面对的降维打击 —— 竞争不再发生在平台与平台之间,而是发生在平台与全新的决策入口之间。
写在最后
当前的 Agent 购物,正处在 “叙事跑在体验前面” 的阶段。技术上模型理解意图与匹配商品的能力还远未达到用户预期,商业上平台也不敢让 AI 真正实现全网比价。当前的真实状态是:传统投流广告不会死,但预算结构会持续重组;直播和短视频在 “制造欲望” 上依然无可替代,但短链路转化会被逐步截留;平台竞争从 “流量之争” 升级为 “AI + 生态 + 履约” 的三位一体竞争。
未来三年是关键观察窗口:究竟是现在的电商巨头能巩固优势,还是新挑战者能掀翻牌桌。
当决策的权力开始交给 AI,所有围绕 “人类注意力” 建立的商业规则,都值得被重新推演一遍。
PS:
1、信息的围墙,会被各大巨头构建的更高更厚,需要监管部门介入才能打通
2、为了避免被“管道化”,各大巨头一定会更拼命的想办法去吸引客户,而不是单纯做一个信息“管道”
3、即使信息被“管道化”,但各大巨头当前建立的生态也很难被击穿
4、传统电商广告和排名,会面临巨大的挑战
5、GEO可能会引入新的攻防大战
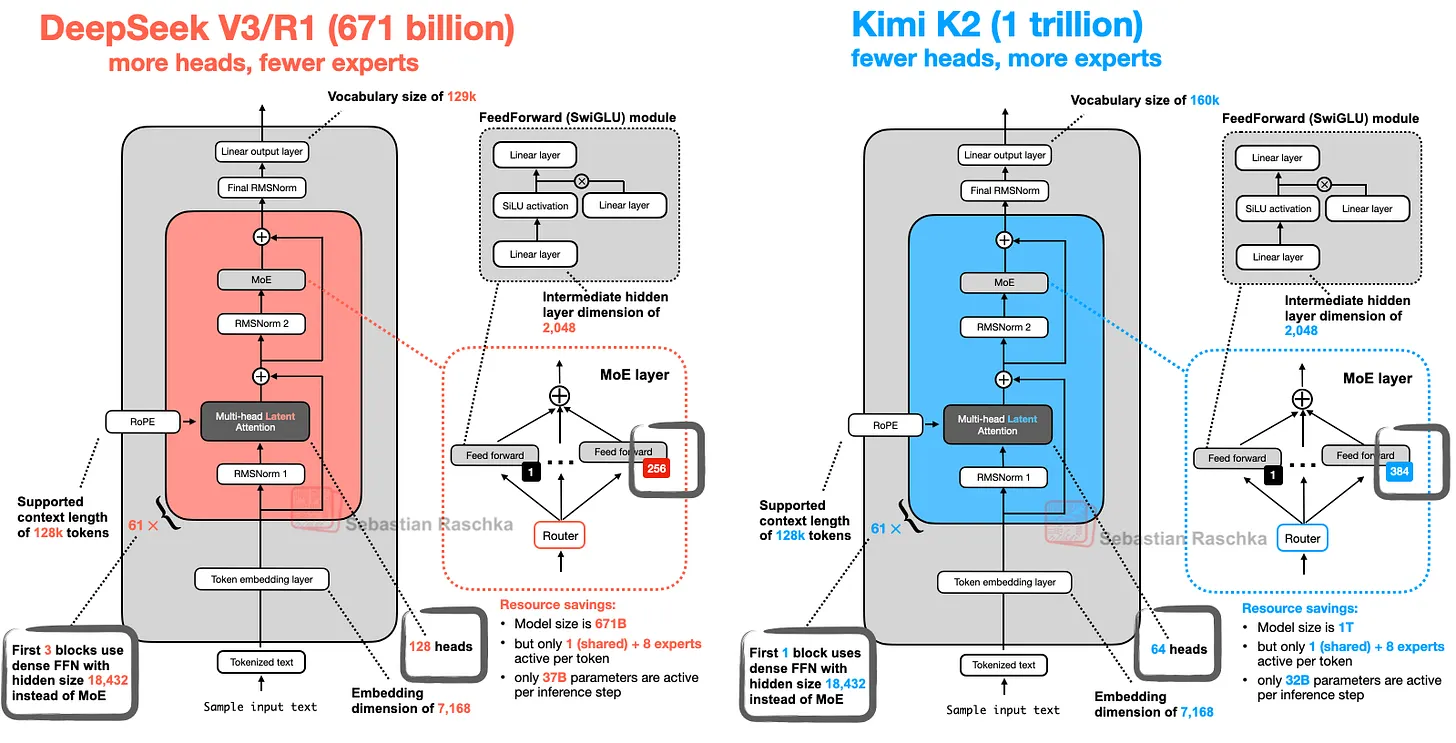


.webp)
.webp)