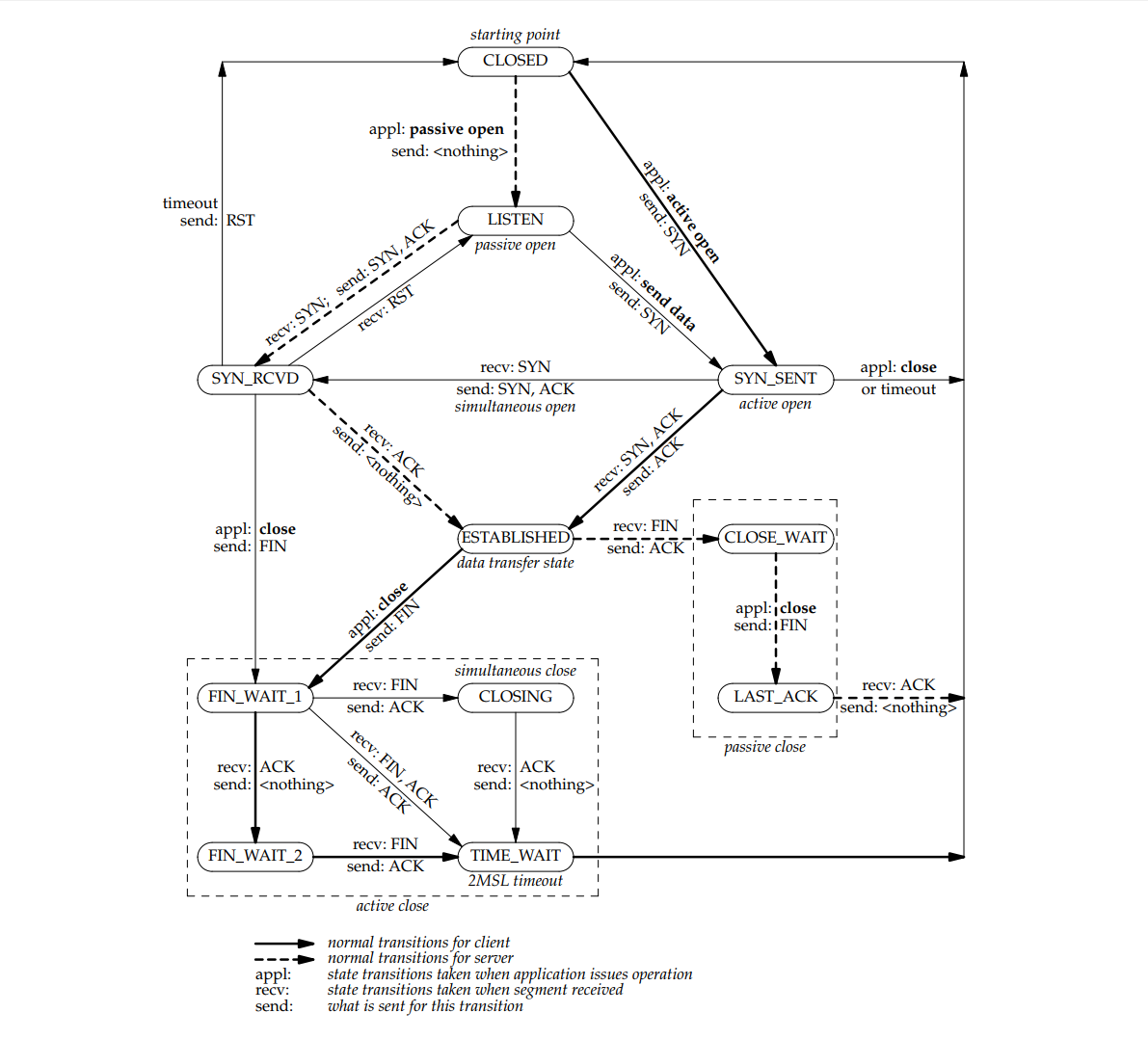
四次挥手过程分析【V5.8,正常流程】
1、客户端主动断开连接,状态从TCP_ESTABLISHED变为TCP_FIN_WAIT1,发送FIN包给服务端
A、状态变为TCP_FIN_WAIT1 tcp_close->tcp_close_state ->tcp_set_state(sk, new_state[TCP_ESTABLISHED]),也就是TCP_FIN_WAIT1 B、发送FIN包 tcp_close->tcp_close_state ->tcp_send_fin
2、服务端收到FIN包,状态从TCP_ESTABLISHED变为TCP_CLOSE_WAIT,并返回ACK包
A、状态变为TCP_CLOSE_WAIT 【tcp_protocol.handler】tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_established ->tcp_data_queue ->->tcp_fin ->->->inet_csk_schedule_ack; 安排ack ->->->sk->sk_shutdown |= RCV_SHUTDOWN; 模拟了close ->->->sock_set_flag(sk, SOCK_DONE); ->->->case TCP_ESTABLISHED: ->->->tcp_set_state(sk, TCP_CLOSE_WAIT); 修改状态 ->->inet_csk(sk)->icsk_ack.pending |= ICSK_ACK_NOW; ACS是否立即发送 B、发送ACK包 【tcp_protocol.handler】tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_established【接上面】 ->tcp_ack_snd_check->__tcp_ack_snd_check->tcp_send_ack
3、客户端收到ACK包,状态从TCP_FIN_WAIT1变为TCP_FIN_WAIT2,然后被替换为状态TCP_TIME_WAIT,子状态TCP_FIN_WAIT2
【tcp_protocol.handler】tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_state_process ->case TCP_FIN_WAIT1: ->tcp_set_state(sk, TCP_FIN_WAIT2); ->tcp_time_wait(sk, TCP_FIN_WAIT2, tmo); ->->tw = inet_twsk_alloc(sk, tcp_death_row, state); ->->->tw->tw_state = TCP_TIME_WAIT; ->->->tw->tw_substate = TCP_FIN_WAIT2; ->->->timer_setup(&tw->tw_timer, tw_timer_handler, TIMER_PINNED);
4、服务端状态从TCP_CLOSE_WAIT变为TCP_LAST_ACK,发送FIN包
A、状态变为TCP_LAST_ACK tcp_close->tcp_close_state ->tcp_set_state(sk, new_state[TCP_CLOSE_WAIT]),也就是TCP_LAST_ACK B、发送FIN包 tcp_close->tcp_close_state ->tcp_send_fin
5、客户端收到FIN包,子状态从TCP_FIN_WAIT2变为TCP_TIME_WAIT,返回ACK包
A、状态和子状态都为TCP_TIME_WAIT 【tcp_protocol.handler】tcp_v4_rcv-> ->if (sk->sk_state == TCP_TIME_WAIT) goto do_time_wait; ->do_time_wait: ->tcp_timewait_state_process ->->if (tw->tw_substate == TCP_FIN_WAIT2) ->->tw->tw_substate = TCP_TIME_WAIT; ->->inet_twsk_reschedule,重新设置回调时间 ->->return TCP_TW_ACK; B、返回ACK ->case TCP_TW_ACK: ->tcp_v4_timewait_ack(sk, skb);
6、服务端收到ACK包,状态从TCP_LAST_ACK变为TCP_CLOSE
【tcp_protocol.handler】tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_state_process ->case TCP_LAST_ACK: ->tcp_done ->->tcp_set_state(sk, TCP_CLOSE);
7、客户端超时回调
A、超时时间定义 #define TCP_TIMEWAIT_LEN (60*HZ) #define TCP_FIN_TIMEOUT TCP_TIMEWAIT_LEN B、超时后,回调tw_timer_handler->inet_twsk_kill,进行inet_timewait_sock清理工作 C、没有找到状态变从TCP_TIME_WAIT变为TCP_CLOSE的代码